国泰君安证券:具身智能,人工智能的下一个浪潮


国泰君安认为,“具身智能”具备人类孩童般的感知和学习行动能力;“具身智能”的基本假设是,智能行为可以被具有对应形态的智能体通过适应环境的方式学习到;Tesla Bot功能进展迅速,商业化前景可期,“算力霸主”英伟达高调布局具身智能;具身智能带来的AI价值远比人形机器人更大。
以下为原文内容:
从符号主义到联结主义,智能体与真实世界的交互得到日益重视。上世纪五十年代的达特茅斯会议之后的一段时期内,对人工智能的研究主要限于符号处理范式(符号主义)。符号主义的局限性很快在实际应用中暴露出来,并催动了联接主义的发展,形成了包括多层感知机、前向神经网络、循环神经网络,直至今日风靡学术界与产业界的深度神经网络等多种方法。这种用人工神经网络模拟认知过程的方法在适应、泛化与学习方面的确取得了很大的进展,但并未真正解决智能体与真实物理世界交互的难题。该难题“莫拉维克悖论”可以通俗地表述为:要让电脑如成人般地下棋是相对容易的,但是要让电脑有如一岁小孩般的感知和行动能力却是相当困难甚至是不可能的。
针对以上问题,“具身智能”(Embodied AI)概念应运而生。针对智能体的交互问题, 明斯基从行为学习的角度提出了“强化学习”的概念。1986年,布鲁克斯从控制论角度出发,强调智能是具身化(Embodied)和情境化 (Contextlized)的,传统以表征为核心的经典AI进化路径是错误的,而清除表征的方式就是制造基于行为的机器人。Rolf Pfeifer在其著作《How the Body Shapes the Way We Think》中通过分析“身体是如何影响智能的”对“智能的具身化”做了清晰的描述,阐明了“具身性”对理解智能本质与研究人工智能系统的深远影响。以上这些工作为人工智能的第三个流派——以具身智能为代表的行为主义方法奠定了坚实基础。
“具身智能”的基本假设是,智能行为可以被具有对应形态的智能体通过适应环境的方式学习到。可以简单理解为各种不同形态的机器人,让它们在真实的物理环境下执行各种各样的任务,来完成人工智能的进化过程。拆分来理解,“具身”的基本含义是认知对身体的依赖性,即身体对于认知具有影响,换句话说,身体参与了认知,影响了思维、判断等心智过程。“具身”意味着认知不能脱离身体单独存在。此外,“具身”相对的概念是“离身”(Disembodiment),指的是认知与身体解耦(ChatGPT为代表的大模型就仅仅实现了离身智能);“智能”代表智能体(生物或机械)通过与环境产生交互后,通过自身学习,产生对于客观世界的理解和改造能力。此外,一些通过强化学习训练的机器人,也可以被认为是具身智能的一种形式,如OpenAI的单手还原魔方机器人等。因此,具身智能旨在基于机器与物理世界的交互,创建软硬件结合、可自主学习进化的智能体。
具身的概念是可检验、可测量的。人所理解的世界概念,其中既包括人类独有的责任心、荣誉、感情、欲望等非具身的概念,也包括了杯子、车等实体以及相应行为的具身概念。而具身概念是具备可达性、可检验性以及可解释性的,即具身的概念对应的实体和行为是可以被测量,可以通过任务的完成来验证以及通过具身学习来实现概念的推断。相比之下,非具身概念基本要素不能实现可测量及可检验。
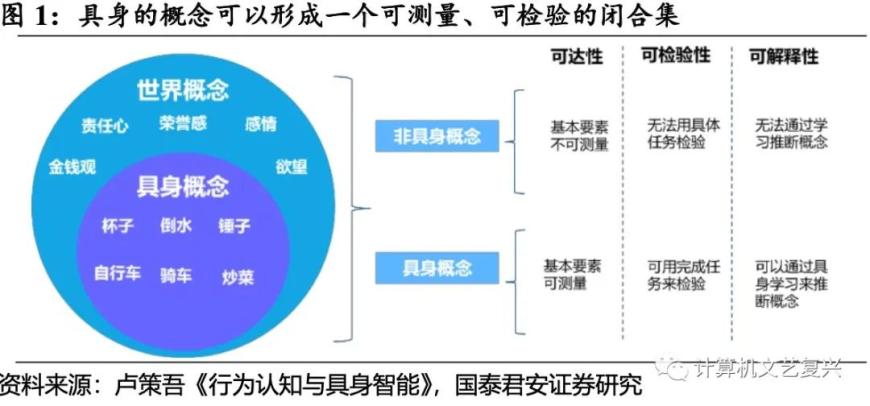
“知行合一”是具身智能的科学立场。根据具身智能的技术实现逻辑,“知”是建立在“行”之上的,也就是说只有通过“具身”才能理解某个场景。比如有个卧室,其具有睡觉、休息、放衣服等行为特征,这类行为是基于人的身体设计的,因此真正理解卧室的场景,就是要能够直接通过坐上椅子、躺在床上等行为任务去验证。同理,机器人通过理解场景,能够实现以上行为才能代表它真正理解了该场景。因为从本质上,物体和场景的类别大多是由功能和任务来定义的,“我能用来干什么,那它是什么”,比如锤子不能叫木棍,锤子有它独特的行为属性。
具身知识在中国古老汉字中都占据较高比例。甲骨文等古老汉字,绝大多数就是通过行为的表征来刻画一个概念,比如“争”的古老写法中,代表两个人的手拔一根绳子,因此,理解行为才是理解概念及场景的关键。

所以,计算机视觉和NLP更多是具身智能的工具,而通用人工智能才是具身智能的终极目标。具身智能要能够实现使用身体(各个部位)完成物理任务的一些现象,比如外国人不会用筷子,但仍能叉起来吃东西,因此具身智能也要通过物理环境完成任务的过程中,表现出完成之前没有覆盖的场景。所以,根据具身智能的特点可以研判,如同经典力学领域的速度、动量、弹性等概念奠基了物理学领域,驱动了后续科学的发展,同理,具身智能因其实现了知识、概念、可解释以及行为因果关系,其有望成为通用人工智能的驱动力。
具身智能首先要具备可供性。可供性意味着要让机器知道物体和场景能够提供的是什么,比如整个身体、部件怎么和场景进行有效拟合。根据《Gendexgrasp: Generalizable dexterous grasping》论文中的案例,用两、三、五根手指去握一个柱子,倘若不同的手都能够产生无误的握杆效果,就代表有了可供性,而物理学正是机器理解可供性的关键。

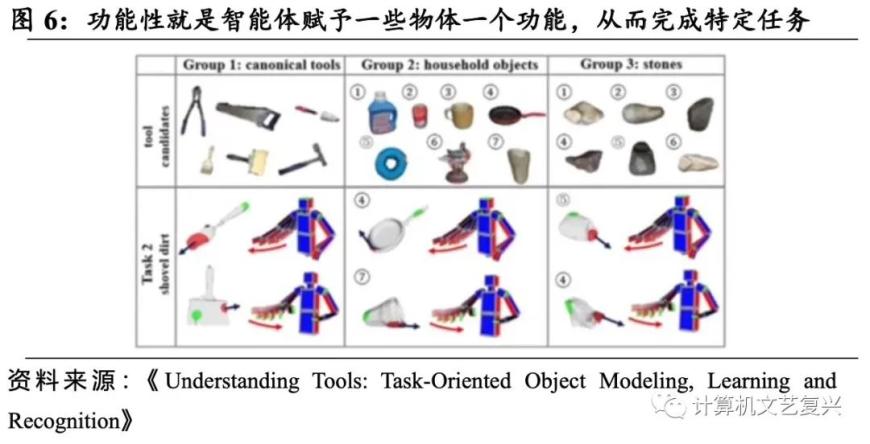
具身智能还要具有功能性。具身智能在把物体作为工具使用的过程中,要能够以任务执行为导向去理解功能。从智能体来理解世界,核心就在于任务——改变实体状态,是任务实现来驱动智能体的。例如,在解决 “铲土”任务过程中,需要实现用不同的工具去铲土,比如杯子、铲子、平底锅等,都要能够让智能体实现“铲土”这个任务。因此,具身智能的功能性就是赋予了物体一个功能,用来解决某个特定任务。
具身智能需要实现因果链。就以上提到的“铲土”例子,智能体能否顺利铲起土来是有因果关系的,例如控制挥动锤子的方式、动量、冲量等指标的改变程度和改变过程,需要用数学和物理的因果链来控制。人工智能研究院朱松纯教授团队介绍了一种学习和规划框架,并证明了所提出的学习和规划框架能够识别对任务成功有重要意义的基本物理量,使智能体能够自主规划有效的工具使用策略,模仿人类使用工具的基本特性。
智能体学习如何使用工具涉及到多个认知和智能过程,这个过程即使对人类来说也并不容易。让机器人掌握工具使用所涵盖的所有技能是一项有挑战性的难题,这项工作包括三个层面:其一是底层的运动控制。很多研究基于阻抗控制(Impedance control)来跟踪工具使用的运动轨迹,或在不同阶段改变力和运动约束,或使用基于学习的方法来控制机器人运动轨迹。在底层控制中,鲁棒地执行运动轨迹是关注的核心。其二是中间层表征。各种利于下游任务的中间表征被提出,以便更好地理解工具的使用。尽管引入这些表征有利于学习更多不同的工具使用技能,但它们目前仍然局限于工具的形状和任务之间的几何关联。其三是理解在工具使用中的涉及的高层概念,比如物体的功能性(Functionality)和可供性(Affordance),以及工具使用中涉及的因果关系与常识,从而实现更好的泛化能力。
现有的具身智能工作大多集中在以上三种基本特性中的某一层面。要么主要关注于机器人的动作轨迹而不去理解任务本身,要么旨在高层次概念理解而过度简化运动规划,都不能够较全面的涵盖所有层面。因此,机器人还远远没有办法基于特定的情境去制定工具使用的策略,并且由于运动学结构的显著差异,机器人观察到的人类使用工具的策略对其来说可能并不是最理想的方式。例如给定一组物体(典型的工具或其他物体),机器人如何判断哪一个会是完成任务的最佳选择?一旦选择了一个物体作为工具,根据机器人和工具特定的运动学结构和动力学限制,机器人该如何有效地使用它?这些问题也正是行业的前沿研究领域。
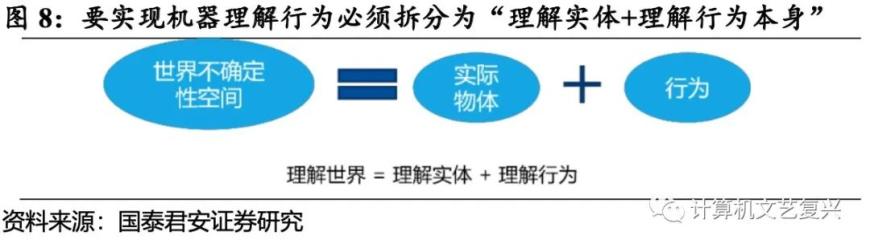
要机器理解实体与行为,就得回答三个核心的科学问题。首先,从机器认知角度,如何让机器看懂行为?其次,从神经认知角度,机器认知语义与神经认知的内在关联如何?再者,从具身认知的角度,如何将行为理解知识迁移到机器人系统?
要实现具身智能,就必须先回答机器能否克隆人类的行为这个问题。行为认知是智能科学中的重要和核心问题,要让机器理解世界代表着:理解实体+理解行为,因为不确定性的世界空间就可以归类为实体与行为两者。
深度学习框架在行为认知中遇到了瓶颈。因为深度学习得到长足发展,计算机视觉领域有两个要素,一个是以物体为中心的感知,一个是以人为中心的感知。配合不断进化的深度学习算法,复杂物体识别可以十分成功,但是要机器明白从人类视角的这个行为的真实语义,却十分困难。市场表现来看也是如此,很多商用产品都是基于物体检测,行为理解的产品都是很少的。之所以人为中心的感知十分困难,是因为深度学习本身达到了瓶颈。根据卢策吾教授的研究结果,行为识别的SOTA要远低于物体识别。
行为理解的关键是要在极大语义噪声中提取行为理解要素。行为是一个抽象概念,因而需要在图像中捕抓行为相关要素。要衡量图像的语义判断区间,可以用语噪比(语噪比=支撑语义判断区间/全图像区间)来刻画,即抹去图像上的某个区域使得其他人无法识别出行为类型的最小区域。卢策吾教授团队通过计算发现,物体识别的语噪比要远大于行为识别,这意味着遮住较大区域仍可以识别物体,但哪怕遮住一小块区域就无法识别行为。因此,可以得出结论,行为理解的关键是要在极大语义噪声中提取行为理解要素,也就是需要在很大干扰情况下,真正挖掘图像的真实语义。而这个工作是无法通过增加深度学习的工作量来达到的。
将行为认知问题分解为感知到知识、知识到推理融合的两个较为简单的阶段,是一个较优的科学路径。离散语义符号是被不同行为所共享的,比如吃饭、读书和打扫都有着“手-握-某物”的标签,通过对这些共享标签的迁移、复用和组合,可以形成行为原语,从而构造“中间层知识”,这种组合可以有着一定的泛化能力,即通过原语组合,机器可以做出没见过的行为。
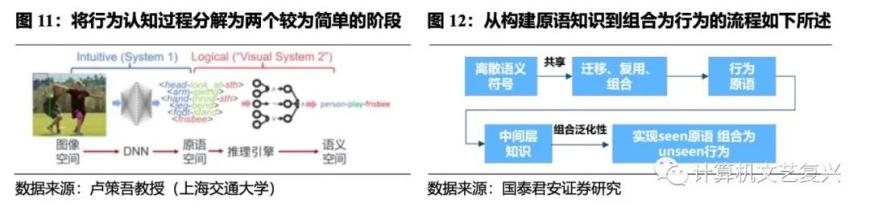
因此,构建海量原语知识以及逻辑规则库是首当其冲的工作。人类理解行为的基本原因,约等于人类各个部件在干什么事情,因此首先得构建大量的基于人类局部状态的原语知识,并能识别它们。其次,有了好的原语检测,之后就需要对它们进行编程,实现逻辑规则引导下的数据驱动学习,但这里容易出的问题是,规则是人类自己认为的,如果规则库错了就会有很大的影响,因此规则学习是解决该问题的办法。具体流程是,在行为原语知识库中随机采样,形成对该行为的判断,然后基于人类给的先验起始点去搜索,规则空间采样,若准确率提高就加上规则,不然就删掉该规则,通过调整后的规则分布形成新规则。卢策吾教授发现,以“人骑车”图像为例,经过以上技术流程,机器可以在未见过的“骑车规则”中自动识别出“骑车”这个行为,所以该技术路线可以有效逼近行为识别的人类性能。

机器能够理解人类行为需要有科学依据的支撑。因此,科学家需要进一步确定机器视觉行为分类特征跟神经特征之间是否存在稳定映射关系。如果有稳定关系,视觉定义行为就是有客观依据的。
实验发现行为从模式到脑信号存在映射,且模型稳定。卢策吾教授联合生物医学团队,搭建了首套大规模视觉理解-神经信号闭环系统,对小鼠的行为模式和神经信号进行了相关性分析。通过实验发现机器学习得出行为从模式到脑信号存在映射,并可以建立一个稳定模型。另外,通过构建一套基于机器学习的行为相关的神经回路发现系统,成功发现解析了“小鼠社会等级”行为的神经回路。综上可以得出结论,通过视觉定义行为是有科学依据的。
不仅仅理解行为,更需要能执行行为,机器能够执行行为才是真正理解行为。通过计算机视觉以及行为认知识别,让机器能够确认和分辨一个行为仅仅只是第一步,这也只是传统旁观式AI学习所达到的功能水平,例如,传统AI学习可以让机器学习“盒子”概念并在新的场景中说出“盒子”这个标签,但在具身智能学习模式中,机器通过感知环境实体,通过亲身体验完成具身学习,最终理解场景并形成“打开”这个概念。因此,当机器可以执行该行为才是具身智能的落脚点。
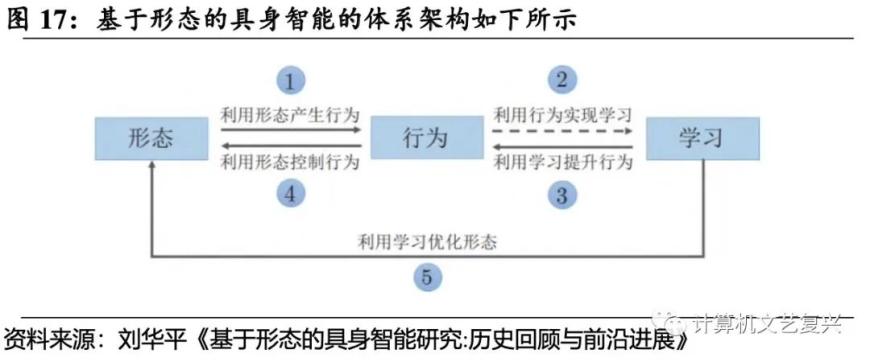
执行行为需要涉及到形态、行为和学习的体系化交互。在基于形态的具身智能中, 形态、行为与学习之间的关系密切。首先,需要利用形态产生行为,该过程重点强调利用具身智能体的形态特性巧妙地实现特定的行为, 从而达到部分取代“计算”的目的。其次,需要利用行为实现学习,重点强调利用具身智能体的探索、操作等行为能力主动获取学习样本、标注信息,从而达到自主学习的目的,此领域当前属于研究前沿。再者,需要强调利用学习提升行为以及利用行为控制形态,后者有多种实现方法,但当前利用学习手段来提升行为,并进而控制形态的工作是现代人工智能技术发展起来后涌现出来的新型智能控制方法,特别是基于强化学习的技术已成为当前的热点手段。最后,具身智能需要利用学习来优化形态,强调利用先进的学习优化技术实现对具身智能体的形态优化设计。
“具身感知”是以执行动作为导向的全概念的交互感知。具身智能首先第一步就得解决具身概念学习的问题,即如何定义、获取、表达可以被机器人使用的物理概念。具身感知和传统计算机视觉不同,计算机视觉没有解析全部的知识,而具身感知包含了“全概念感知”和“交互感知”,从而保证机器看到的不是标签,而是怎么利用它。例如,可以从人类认知的角度,构建大规模关节体知识库,该知识库涵盖外形、结构、语义、物理属性,同时标注关节体每个部件的质量、体积、惯性等,记录真实世界物体操作力反馈与仿真操作力反馈,在物理属性知识加持下,物体力反馈曲线可以完全拟合出来,这时候仿真物体操作的时候,不再是去检测标签,而是所有知识全部检测出来,检测出来后,可以通过机器执行的准确率,判断感知的准确率。
通过行为的反馈和模式学习的空间压缩,可以实现“具身执行”的一定泛化性。在交互感知下,机器如果只是看物体,信息量没有增加,但如果交互它,就能迅速减少误差。机器面对物体,初步检测它的知识,但肯定存在知识结构不准的情况,但可以在猜测它是怎么做出这个行为的基础上,指导机械去做,倘若做完之后跟真实不一样,就证明猜测有问题,再反过来优化问题。并且,可以把抓取到的所有特征模式,压缩到可以被学习的空间范围内,通过这种机制,机器在面对没见过的物体时,也能进行相关的行为,因而具备了一定的通用性。
Tesla Bot功能进展迅速,商业化前景可期。2021年,在“特斯拉AI日”上,马斯克发布了特斯拉的通用机器人计划,并用图片展示了人形机器人Tesla Bot的大致形态。但当时的Tesla Bot只是个概念。一年后在2022特斯拉AI日上,人形机器人擎天柱(Optimus)实体亮相。2023年5月中旬的特斯拉股东大会上,马斯克又展示了Tesla Bot的最新进展,现在Tesla Bot已经可以流畅行走,并还能灵活抓取放下物体。马斯克在会上表示“人形机器人将会是今后特斯拉主要的长期价值来源。如果人形机器人和人的比例是2比1,则人们对机器人的需求量可能是100亿乃至200亿个,远超电动车数量”。
最近的Tesla Bot功能突破来源于特斯拉改进的电机扭矩控制以及环境建模等技术。特斯拉利用一些技术方法改进了人形机器人的动作和控制,包括电机扭矩控制、环境发现与记忆、基于人类演示训练机器人。首先,研究团队使用电机扭矩控制(motor torque control)操纵人形机器人腿部的运动,让机器人落脚力度保持轻缓。对于一个机器人来说,观察或感知周围环境是非常重要的,因此特斯拉为人形机器人添加了环境发现与记忆的能力。现在该人形机器人已经可以对周围环境进行大致建模。特斯拉的人形机器人具备与人类相似的身体结构,特斯拉的研究团队使用大量人类演示训练了机器人,特别是在手部动作方面,旨在让其具备与人类似的物体抓取能力。
具身智能带来的AI价值远比人形机器人更大。具身智能最大的特质就是能够以主人公的视角去自主感知物理世界,用拟人化的思维路径去学习,从而做出人类期待的行为反馈,而不是被动的等待数据投喂。人形机器人提供了各种基于人类行为的学习和反馈系统,为实现更复杂行为语义提供了迭代的基础和试验场,因此,人形机器人的逐步完善也为具身智能的落地提供了方向。而面向工业等场景的具身智能应用并非一定要是人形机器人,因此具身智能背后的技术和方法论才是核心,也意味着具身智能所带来的价值要远远高于人形机器人本身。换句话说,人形机器人是具身智能的重要应用场景,也将为具身智能的迭代优化提供方向和空间。
强化学习兴起之后,具身智能受到了更广泛的关注。之前随着Alpha Go的成功,学术界对于强化学习的兴趣大增,随之很多人开始用RL来打通智能体的感知-决策-执行,希望实现具身智能。训练RL是一个不断试错的过程,所以从2017、18年开始,出现了很多仿真训练平台,能把一个智能体以具身的形式放进去,然后通过与环境的交互中获得reward,进而学习一个policy。但是因为仿真环境和现实环境总是有差距的(叫sim2real gap),习得的policy不一定能迁移到现实里。当前能实现技能policy从仿真迁移到现实环境中的,主要还是像移动导航、单步骤的抓取或者操作这类较为单一的技能,而且很难泛化。
最近大语言模型的风头又压过了强化学习。最近业界希望通过大规模sequence to sequence,用一个模型整合视觉、语言、机器人,也取得了一定效果。但是机器人的执行需要的是4D数据(三维环境和机器人运动的时序轨迹),它的数据量和丰富度都远不如图片和文本,采集成本也高的多,因此迭代演化的难度相比于大模型高得多。
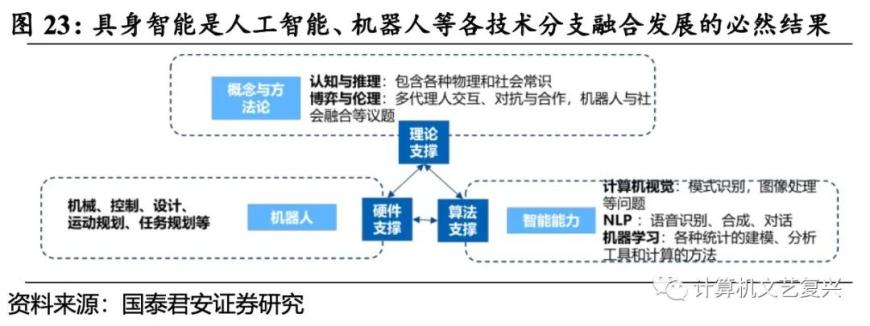
而多模态大模型为具身智能的技术瓶颈突破提供了重要驱动力。具身智能是人工智能、机器人等各技术分支融合发展的必然结果,因为计算机视觉为图像的采集和处理打开了窗口,图形学也为物理仿真提供了工具支撑,NLP也为人类-机器交互提供了便捷性,也为机器从文本中学习知识提供了有效途径,认知科学也为具身智能的行为认知原理提供了科学研究途径。各类机器人构件也为智能体与物理环境交互提供了桥梁。因此,人工智能的技术分支以及机器人功能性的提升,为具身智能的进一步发展带来了可能,而当前AIGC时代的大模型可以将之前的技术分支更优地集成和创新,已有不少研究者尝试将多模态的大语言模型作为人类与机器人沟通的桥梁,即通过将图像、文字、具身数据联合训练,并引入多模态输入,增强模型对现实中对象的理解,从而更高效地帮助机器人处理具身推理任务,一定程度提升了具身智能的泛化水平。所以,GPT等AI大模型为具身智能的自我感知和任务处理的优化升级提供了新的研究手段。
“算力霸主”英伟达高调布局具身智能。在ITF World 2023半导体大会上,黄仁勋表示人工智能的下一个浪潮将是具身智能,即能理解、推理、并与物理世界互动的智能系统。同时,他也介绍了英伟达的多模态具身智能系统Nvidia VIMA,其能在视觉文本提示的指导下,执行复杂任务、获取概念、理解边界、甚至模拟物理学,这也标志着AI能力的一大显著进步。
融合传感器模态与语言模型,谷歌推出的视觉语言模型相较于ChatGPT新增了视觉功能。2023年3月,谷歌和柏林工业大学AI研究团队推出了当时最大视觉语言模型——PaLM-E多模态视觉语言模型(VLM),该模型具有5620亿个参数,集成了可控制机器人的视觉和语言能力,将真实世界的连续传感器模态直接纳入语言模型,从而建立单词和感知之间的联系,且该模型能够执行各种任务且无需重新训练,其相较于ChatGPT新增了视觉功能。PaLM-E的主要架构思想是将连续的、具体化的观察(如图像、状态估计或其他传感器模态)注入预先训练的语言模型的语言嵌入空间,因此实现了以类似于语言标记的方式将连续信息注入到语言模型中。
谷歌实现视觉语言与机器人高水平实时互联,且观察到了类似多模态思维链推理与多图像推理等涌现能力的出现。基于语言模型,PaLM-E 会进行连续观察,例如接收图像或传感器数据,并将其编码为一系列与语言令牌大小相同的向量。因此,模型就能继续以处理语言的方式“理解”感官信息。而且,同一套PaLM-E模型能够达到实时控制机器人的水准。PaLM-E 还展现出随机应变的能力,例如尽管只接受过单图像提示训练,仍可实现多模态思维链推理(允许模型对包含语言和视觉信息在内的一系列输入进行分析)和多图像推理(同时使用多张输入图像进行推理或预测)。但谷歌展示的Demo中的空间范围、物品种类、任务规划复杂度等条件还比较有限,随着深度学习模型愈发复杂,PaLM-E也将打开更多可行性应用空间。
微软正计划将ChatGPT 的能力扩展到机器人领域,使得能用语言文字控制机器人。目前实验已经能够通过给ChatGPT的对话框输入指令,让其控制机器人在房间中找到“健康饮料”、“有糖和红色标志的东西”等。微软研究人员表示,“研究的目标是看ChatGPT是否能超越生成文本的范畴,对现实世界状况进行推理,从而帮助机器人完成任务”。微软希望帮助人们更轻松地与机器人互动,而无需学习复杂的编程语言或有关机器人系统的详细信息。
阿里采用和微软相似的路径,正在实验将千问大模型接入工业机器人。在近日举行的第六届数字中国建设峰会上,阿里云发布一个演示视频中展示了千问大模型的实际应用场景。其中,千问大模型接入了工业机器人,工程师通过钉钉对话框向机器人发出指令后,千问大模型在后台自动编写了一组代码发给机器人,机器人开始识别周边环境,从附近的桌上找到一瓶水,并自动完成移动、抓取、配送等一系列动作,递送给工程师。在钉钉对话框输入一句人类语言即可指挥机器人工作,这将为工业机器人的开发和应用带来革命性的变化,其背后意味着大模型为工业机器人的开发打开了新的大门。因为千问等大模型为机器人提供了推理决策的能力,从而有望让机器人的灵活性和智能性大幅提升。




- 银行股迎来“黄金买点”?摩根大通预计下半年潜在涨幅高达15%,股息率4.3%成“香饽饽”
- 华润电力光伏组件开标均价提升,产业链涨价传导顺利景气度望修复
- 我国卫星互联网组网速度加快,发射间隔从早期1-2个月显著缩短至近期的3-5天
- 光伏胶膜部分企业上调报价,成本增加叠加供需改善涨价空间望打开
- 广东研究通过政府投资基金支持商业航天发展,助力商业航天快速发展
- 折叠屏手机正逐步从高端市场向主流消费群体渗透
- 创历史季度新高!二季度全球DRAM市场规模环比增长20%
- 重磅!上海加速推进AI+机器人应用,全国人形机器人运动会盛大开幕,机器人板块持续爆发!
- 重磅利好!个人养老金新增三大领取条件,开启多元化养老新时代,银行理财产品收益喜人!
- 重磅突破!我国卫星互联网组网速度创新高,广东打造太空旅游等多领域应用场景,商业航天迎来黄金发展期!


