

报告导读
以超异构创新重塑大规模AI计算,占GPU市场近80%份额,数据中心业务高速增长,成为世界AI的增长引擎。
投资要点
首次覆盖,给予“增持”评级。英伟达作为行业龙头当仁不让,考虑到其1QFY2024营收的出色表现,包括数据中心收入创下42.8亿美元的纪录,以及英伟达自身对于2QFY2024的收入展望达110.0亿美元的乐观预期,我们预计公司FY2024E/FY2025E/FY2026E营业收入分别为400.0/516.26/620.0亿美元,同增48.29%/ 29.07%/ 20.09%,FY2024E/FY2025E/FY2026E经调整净利润分别为151.96/223.07/285.79亿美元,同增247.89%/ 46.80%/ 28.12%。
英伟达以超异构创新构建面向大规模AI计算的系统性竞争优势。英伟达面向AI时代大规模并行计算,进行了全栈系统的优化。英伟达芯片互联通信技术NVLink性能快速迭代,GPU + Bluefield DPU + Grace CPU的结合开创性地实现了芯片系统间的高速通信互联。同时CUDA充当通用平台,引入英伟达软件服务和全生态系统。我们认为,芯片和系统耦合的实现使得英伟达真正实现了超异构创新。
GH200超级芯片是英伟达产品与技术的集大成者。我们认为,GH200集合了最先进的Grace Hopper架构,并应用第四代Tensor Core提升计算性能、进行模型优化,NVLink实现了高速的传输,尤其是NVLink改变了传统PCIe复杂的传输过程,满足了在每个GPU之间实现无缝高速通信的需求,构建起了芯片间的高速互联系统,将进一步形成英伟达的竞争壁垒。
英伟达作为龙头企业将大比例享受AI芯片行业整体需求高增带来的红利。IDTechEx预测2033年全球AI芯片市场将增长至2576亿美元;JPR预测2022-2026年全球GPU销量复合增速将保持在6.3%水平。英伟达作为业内有目共睹的头部公司,产品生态具备显著的稀缺性,将在算力领域充分受益,享受市场爆发带来的客户需求高增。
风险提示:AI应用发展不及预期;公司研发进度不及预期;地缘政治冲突影响产品销售。

目录


报告正文
1
一台不断学习进化的机器,
三十年打造生态帝国
1.1.图形芯片时代开端,帝国之路就此开启
英伟达成立于1993年,怀揣打造图形芯片时代愿景。英伟达(NVIDIA)总部位于美国加利福尼亚州圣克拉拉市,依托硅谷作为全球电子工业基地的地缘优势,1993年,黄仁勋、克里斯(Chris A.Malachowsky)与普雷艾姆(Curtis Priem)怀着 PC 有朝一日会成为畅享游戏和多媒体的消费级设备的信念,共同创立了英伟达。

1.2.多方求索重塑行业,重新定义现代图形
1.2.1. 1993年-1998年:萌芽期
图形芯片市场竞争日益激烈,英伟达多方探索寻求突破。英伟达成立之初,市场上仅有20余家图形芯片公司。1994年,英伟达与SGS-THOMPSON首次开展战略合作;1995年,英伟达推出其首款显卡产品NV1,配备了基于正交纹理映射的2D/3D图形核心,支持2D、3D处理能力的同时还拥有音频处理能力;1996年,英伟达推出首款支持Direct3D的Microsoft DirectX 驱动程序;1997年,英伟达发布全球首款128位3D处理器RIVA 128,发布后四个月内销量超100万台,但此时,图形芯片这一市场的竞争者已飙升至70家,英伟达深陷财务泥淖,最终决定将研发和生产重心放在2D/3D的PC专用融合显卡领域;1998年,英伟达与台积电签订多年战略合作伙伴关系,台积电开始协助制造英伟达产品。


1.2.2. 1999年-2005年:成长期
1999年发明GPU,行业重塑之路就此开启。GeForce 256是由英伟达发布的全球首款GPU, 英伟达将GPU定义为“具有集成变换、照明、 三角设置/裁剪和渲染引擎的单芯片处理器,每秒可处理至少1000万个多边形”。同年,英伟达推出适用于专业图形的Quadro GPU,并宣布以每股12美元的价格首次公开募股。2000年,显卡先驱3dfx因先前拒绝使用微软Direct3D通用API标准而导致其显卡通用性降低, 并因其市场战略的失误,最终被英伟达低价收购;2003年,英伟达收购无线领域图形和多媒体技术领导者MEDIA Q,2004年,NVIDIA SLI问世,大大提升了单台PC的图形处理能力。

1.2.3. 2006年-2014年:成熟期
CUDA打造GPU计算的开发环境,硬件+软件生态帝国初现。2006年,英伟达推出基于通用GPU计算的CUDA架构,借助CUDA和GPU的并行处理能力,英伟达收获了开发者庞大的用户群;2007年,英伟达推出Tesla GPU,让此前只能在超级计算机中提供的计算能力被更广泛的应用;2008年,Tegra移动处理器问世,其能耗约为一般的PC笔记本的三十分之一;2013年,四核移动处理器Tegra 4发布;2014年,英伟达推出192核超级芯片Tegra K1和平板电脑SHIELD tablet。至此,英伟达的几大产线均逐步成熟,应用行业逐步扩张,产品生态逐步健全。


1.2.4. 2015年至今:转型期
深度学习需求催化英伟达产品转型,为AI革命注入强劲动力。2015年,搭载256核移动超级芯片的Tegra X1的NVIDIA DRIVE问世,其可用于驾驶辅助系统,为自动驾驶汽车技术发展铺平了道路,也标志着英伟达正式投身深度学习领域;2016年,英伟达推出第11代GPU架构PASCAL、首款一体化深度学习超级计算机DGX-1和人工智能车辆计算平台DRIVE PX 2,相较CPU而言,DGX-1可将深度学习训练速度提高96倍;2017年,更适合超算的Volta架构发布;在随后的几年里,Turing、Ampere等架构陆续发布,持续助力AI革命。


1.3.组织架构明晰,管理团队专业
组织架构服务产品业务条线,管理团队权责清晰。据theofficialboard,英伟达的组织架构清晰,技术和运营部门较为庞大,各大核心业务条线均有团队专门负责。英伟达官网招聘信息显示,英伟达定义的其核心业务部门包括AI、研究和硬件三大类。我们认为,公司组织架构设置平行于产品业务,有助于发挥研究者的专项技术才能,并强调研究的前瞻性和突破性。同时,以黄仁勋为首的管理团队具有专业的业务背景与管理才能,公司管理层与董事会均由经验丰富的人士担任。


1.4.黄仁勋:不止是CEO,更是精神领袖
作为创始人、CEO与精神领袖,黄仁勋带领英伟达创造AI龙头奇迹。黄仁勋,1963年出生于中国台北,美籍华人。作为公司创始人,黄仁勋历经30载依旧任英伟达的总裁兼首席执行官。他曾被《哈佛商业评论》和Glassdoor评为全球最佳CEO和受雇员评价最高的CEO。2021年9月,黄仁勋登上《时代》杂志封面,成为《时代》杂志2021年世界最具影响力的百位人物之一。
兼具技术与业务背景,葆有实干与远见特质。黄仁勋1984年于俄勒冈州立大学取得学士学位,1990年获得斯坦福大学硕士学位,1983-1985年间,其担任AMD芯片工程师,而后跳槽至LSI Logic继续从事芯片设计,在LSI Logic任职期间,黄仁勋转岗销售部门,因其出色的表现很快晋升为部门经理,从此踏上管理岗位。在1993年英伟达筹建之初,因其出色的技术和业务背景,克里斯与普雷艾姆推举黄仁勋担任英伟达总裁兼CEO。2020年,黄仁勋获颁台湾大学名誉博士学位,以表彰其在人工智能与高效能计算领域的伟大贡献。
2
技术与产品高筑壁垒,让 AI 照进现实
细分英伟达的产品线,我们可将其划分为硬件产品、软件平台、应用框架三个维度。同时英伟达基于“硬件+软件”的技术优势,同时依托面向行业打造的应用框架,提供了对于细分行业定制的行业解决方案。

2.1. 硬件产品始于GPU,但不止GPU
英伟达首创GPU产品,推动处理器中逻辑运算单元数量增长。CPU是电脑的中央处理器,同时也是电脑的控制和运算核心,能够解释计算机发出的指令。而GPU是电脑的图形处理器,最初主要用于进行图像运算工作。英伟达研发世界上首款GPU GeForce 256,开GPU之先河,令GPU逐渐演化为普遍使用的并行处理器。整体而言,GPU和CPU同为基于芯片的微处理器,是重要的计算引擎。CPU拥有更大的逻辑运算单元和控制单元,同时拥有更大的缓存空间,但GPU却拥有更多的逻辑运算单元数量。

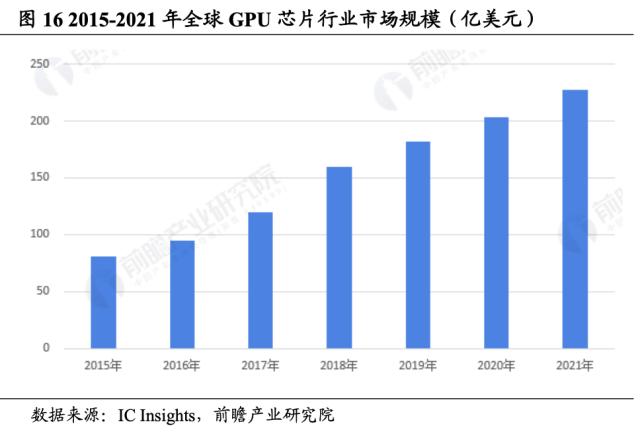
需求激增催化 GPU 市场规模爆发式增长。IC Insights 数据显示,2015 年至 2021 年间,全球 GPU 芯片市场规模年均增速超 20%,2021年,全球 GPU 芯片市场规模已超过 220 亿美元,全年出货总量超过 4.6亿片。我们认为,目前 GPU 仍占全球 AI 芯片的主导地位。
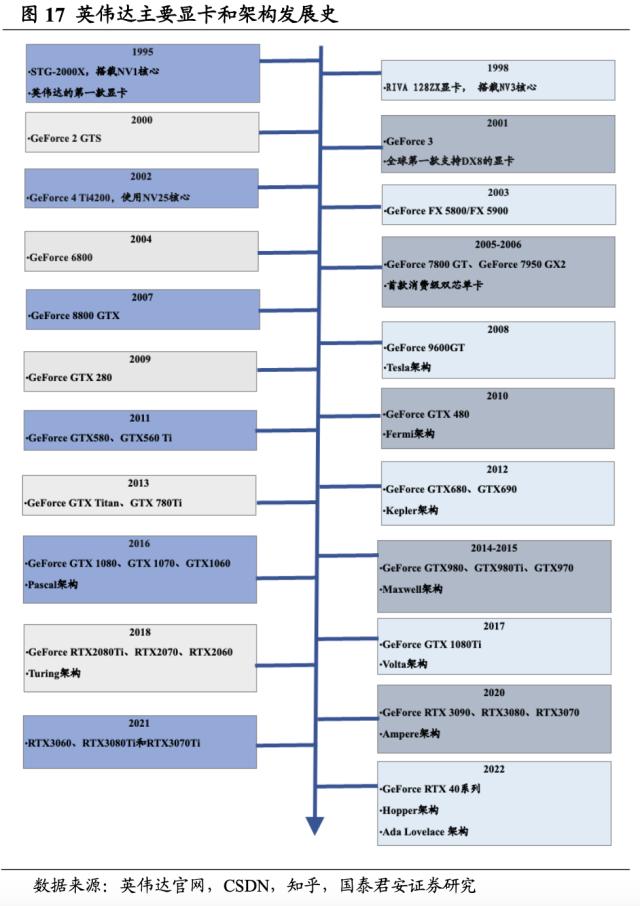
英伟达深耕 GPU 业务,主要显卡产品更迭迅速。英伟达主要显卡产品以 GeForce 为前缀命名,自 2000 年发布 GeForce 2 GTS 起,GeForce系列划分出多种型号,直至目前,英伟达在售的主要显卡产品包括GeForce16、GeForce20、GeForce30、GeForce40 等。从 GPU 架构角度,自 2008 年发布 Tesla 架构后,英伟达依次发布了 Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere、Hopper、AdaLovelace 等 GPU 微架构,近年来 GPU 架构的更新速度显著加快。
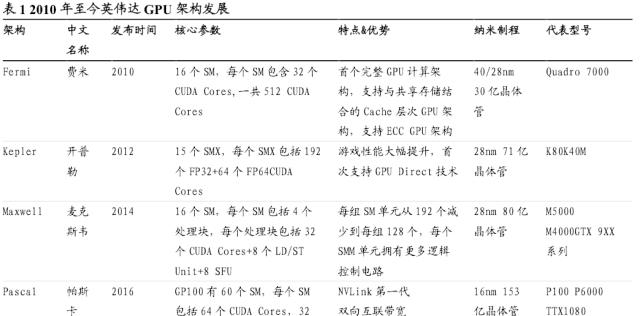
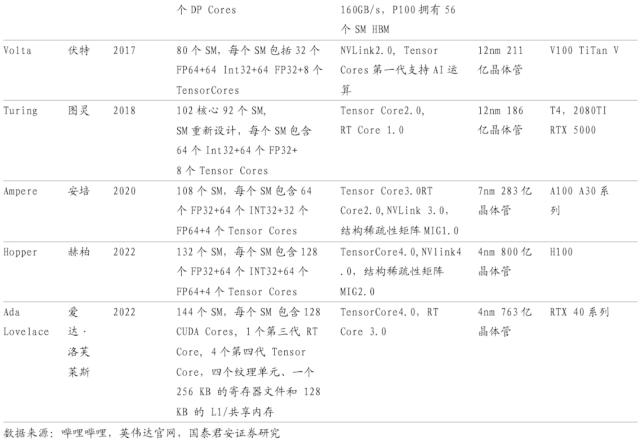
Ada Lovelace 架构为英伟达 GeForce RTX 40 系列显卡提供动力支持。Ada Lovelace 架构主要用于游戏显卡的生产,其采用的第四代 TensorCore 使用首次推出的全新 FP8 Transformer 引擎,能够提升四倍吞吐量;其中的第三代 RT Core 配备全新 Opacity Micromap 和 Displaced Micro-Mesh 引擎,可大幅提升进行光线追踪的速度,所占用的显存只有之前的二十分之一;并且,Ada Lovelace 架构可使用 DLSS 3(深度学习超采样)算法,可对多个分辨率较低的图像进行采样,并使用先前帧的运动数据和反馈来重建原生质量图像,从而创建更多高质量帧,显著提升 FPS(Frames per second),目前已应用于 200 多款游戏和应用。


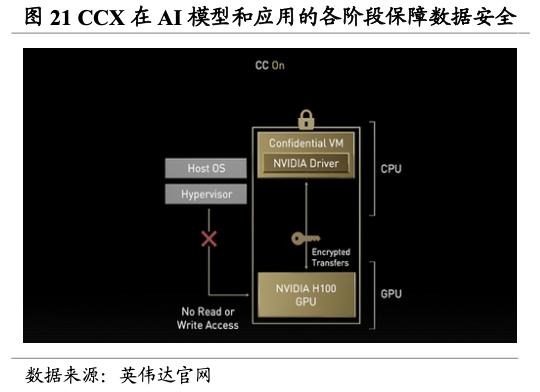
Hopper 架构为加速计算实现新的巨大飞跃。与 Ada Lovelace 架构不同,Hopper 架构主要用以打造加速计算平台。Hopper 架构以Transformer 为加速引擎,其中的 Hopper Tensor Core 能够大幅加速Transformer 模型的 AI 计算。Hopper 架构同时搭载 NVLink Switch 系统,NVLink 作为一种纵向扩展互联技术,与新的外部 NVLink 交换机结合使用时,系统可以跨多个服务器以每个 GPU 900 GB/s 的双向带宽扩展多 GPU IO,能够满足每个在 GPU 之间实现无缝高速通信的多节点、多 GPU 系统的需求。同时,Hopper 架构还采用了具有机密计算功能的加速计算平台 CCX,以保障数据处理期间的 GPU 使用安全。

GeForce RTX 40显卡基于Ada Lovelace架构打造。英伟达最新的显卡为GeForce RTX 40系列,GeForce RTX 40搭载英伟达最先进的GPU,其采用新型SM多单元流处理器将性能功耗比提升2倍,并应用第四代Tensor Core提升计算性能,达到1.4 Tensor-petaFLOPS,同时,搭载的第三代RT Core实现了光线追踪性能的两倍提升,可模拟真实世界中的光线特性,能够显著提升玩家游戏体验。

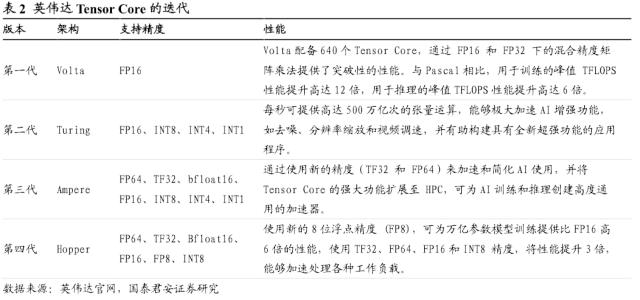
Tensor Core是自Volta架构以来英伟达的核心技术,为HPC和AI实现大规模加速。Tensor Core 可实现混合精度计算,动态调整算力,从而在保持准确性的同时提高吞吐量,Tensor Core提供了一整套精度(TF32、Bfloat16 浮点运算性能、FP16、FP8 和 INT8等),确保实现出色的通用性和性能。目前,Tensor Core已广泛用于AI训练和推理。
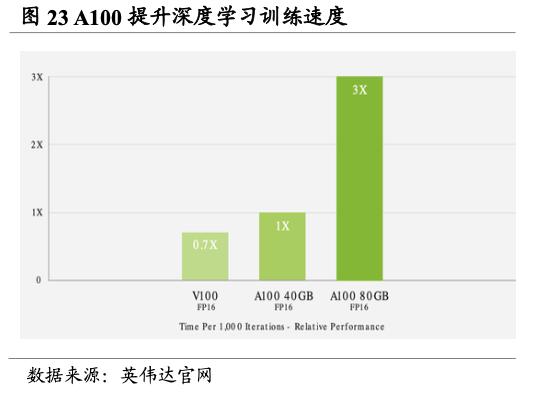
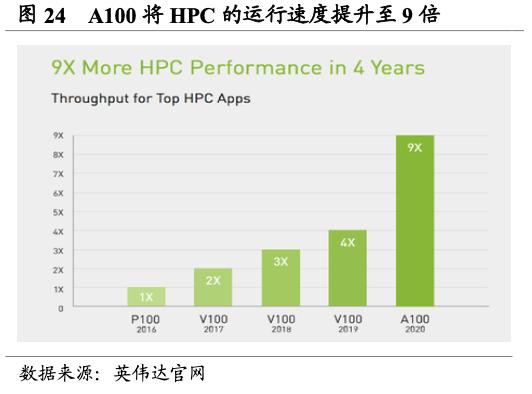
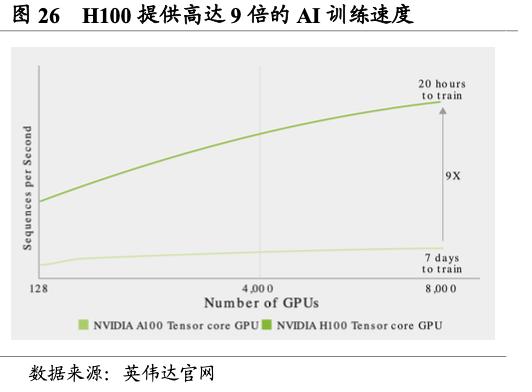
从A100到H100为AI训练和推理带来历史性变革,成就加速计算的数量级飞跃。H100的上一代产品,2020年推出的A100,较2016年的P100已在四年间将高性能计算的运行速度提升至9倍,但H100真正实现了数量级的飞跃。H100基于Hopper架构的卓越优势,配备第四代Tensor Core和Transformer引擎,使双精度Tensor Core的每秒浮点运算量提升3倍。与A100相比,H100可为多专家模型(MoE)提供高九倍的训练速度。推理端,H100表现同样优越,H100可将推理速度提高至A100的30倍,并提供超低的延迟,在减少内存占用和提高计算性能的同时,大语言模型的准确度仍旧得到保持。

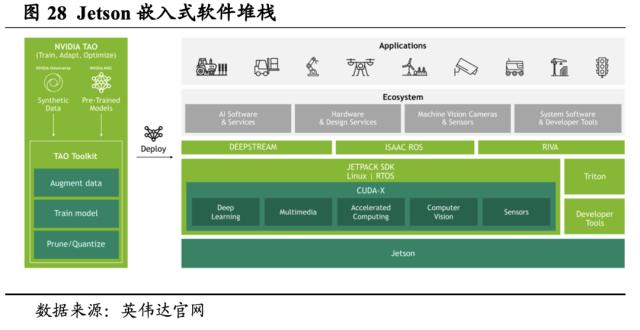
Jetson嵌入式系统打造灵活且可拓展的嵌入式硬件解决方案。Jetson是用于自主机器和其他嵌入式应用的先进平台,该平台包括Jetson模组、用于加速软件的JetPack SDK,以及包含传感器、SDK、服务和产品的生态系统。其中,每一个Jetson均包含了CPU、GPU、内存、电源管理和高速接口,是一个完整的系统模组,并且所有 Jetson 模组均由同一软件堆栈提供支持,意味着企业只需一次开发即可在任意地方部署。目前英伟达在售的Jetson主要包括Jetson Orin系列、Jetson Xavier系列、Jetson TX2系列和Jetson Nano,能够在数据中心和云部署的技术基础上为AI应用提供端到端加速。
以Jetson Orin为例,Jetson Orin模组可实现每秒275万亿次浮点运算(TOPS)的算力,性能是上一代产品的8倍,可适用于多个并发AI推理,此外它还可以通过高速接口为多个传感器提供支持,这使得 Jetson Orin 成为机器人开发新时代的理想解决方案。量产级Jetson Orin模组能够为企业提供在边缘构建自主机器所需的性能和能效,以帮助企业更快地进入市场。并且英伟达提供Jetson AGX Orin开发者套件,可实现对整个Jetson Orin模组系列进行模拟。

Jetson与VIMA将有望与具身智能相结合,直面AI的下一波浪潮。具身智能是能理解、推理、并与物理世界互动的智能系统。ITF World 2023半导体大会上,黄仁勋表示,人工智能下一个浪潮将是"具身智能",同时英伟达也公布了Nvidia VIMA,VIMA是一个多模态具身人工智能系统,能够在视觉文本提示的指导下执行复杂的任务。我们认为,伴随着Jetson和VIMA的系统逐步研发完善,英伟达将成为推动具身智能发展的引领者。
整体而言,英伟达在边缘的优势能够为扩大市场提供更多可能性。通过使用Jetson,企业可以自由开发和部署 AI 赋能的机器人、无人机、IVA 应用和其他可以自我思考的自主机器。中小企业和初创企业能够承担Jetson的部署开销,以此开发自主机器和其他嵌入式应用,且英伟达在嵌入式技术领域同时具有领先优势,我们对其市场积极看好。
2.2.软件平台带来更多可能,奠定生态帝国基石
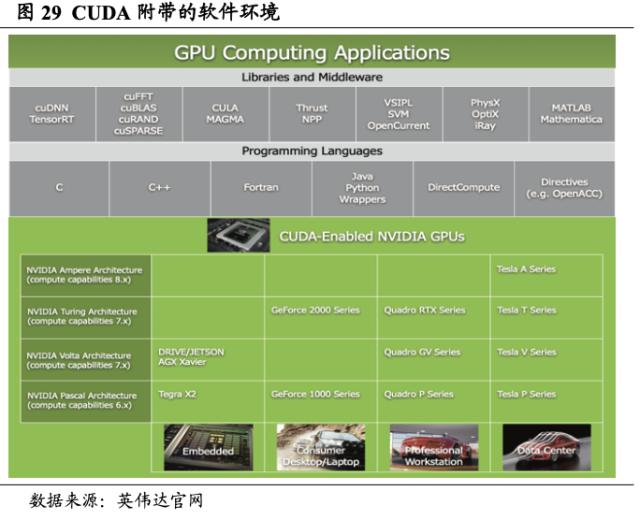
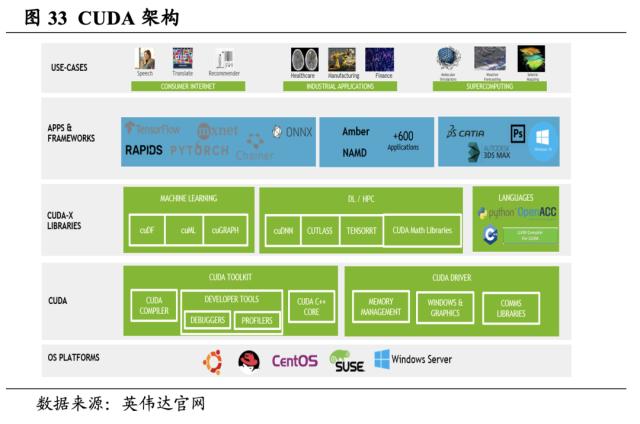
CUDA构筑软件业务底层框架基石,打造对接行业解决方案的开发平台。英伟达于2006年发布CUDA,成为首款GPU通用计算解决方案。借助 CUDA 工具包,开发者可以在GPU加速的嵌入式系统、桌面工作站、企业数据中心、基于云的平台和HPC超级计算机上开发、优化和部署应用程序。CUDA工具包主要包括GPU加速库、调试和优化工具、C/C++ 编译器以及用于部署应用程序的运行环境库。不论是图像处理、计算科学亦或是深度学习,基于CUDA开发的应用都已部署到无数个GPU中。
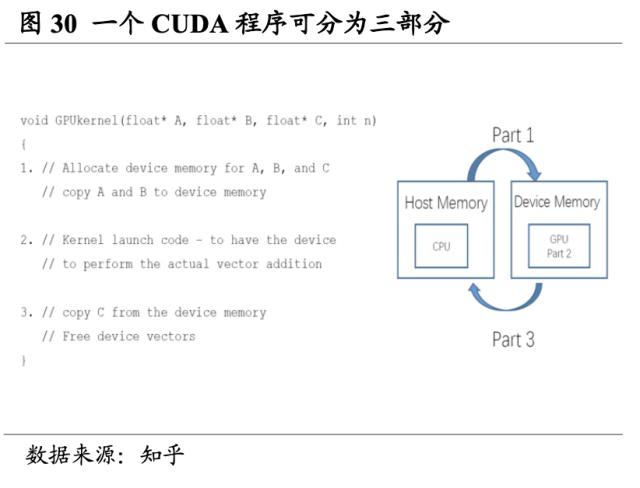
开发者从此不再需要通过写大量的底层语言代码对GPU进行调用。CUDA与C语言的框架较为接近,作为一种类C语言,CUDA对于开发者而言上手难度较小,且同时也支持Python、Java等主流编程语言。此外,一个CUDA程序可分为三个部分:第一,从主机端申请调用GPU,把要拷贝的内容从主机内存拷贝到GPU内;第二,GPU中的核函数对拷贝内容进行运算;第三,把运算结果从GPU拷贝到申请的主机端,并释放GPU的显存和内存,整个过程较为清晰且易操作。可以说,CUDA是搭建了一个帮助开发者通过高级编程语言使用GPT完成特定行业需求功能的平台,英伟达也因此打造了一个“硬件+软件平台”的生态帝国。
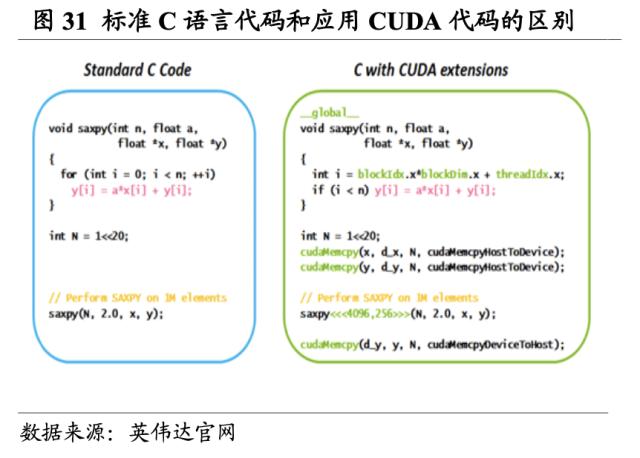
打造软件加速库的集合CUDA-X AI,帮助现代AI应用程序加速运行。CUDA-X AI作为软件加速库集合,建立在CUDA之上,它的软件加速库集成到所有深度学习框架和常用的数据科学软件中,为深度学习、机器学习和高性能计算提供优化功能。库包括 cuDNN(用于加速深度学习基元)、cuML(用于加速数据科学工作流程和机器学习算法)、TensorRT(用于优化受训模型的推理性能)、cuDF(用于访问pandas等数据科学 API)、cuGraph(用于在图形上执行高性能分析),以及超过13个的其他库。CUDA-X AI已成为领先的云平台,包括AWS、Microsoft Azure和Google Cloud在内的一部分,而且可以通过NGC网站逐个地或作为容器化的软件栈免费下载。
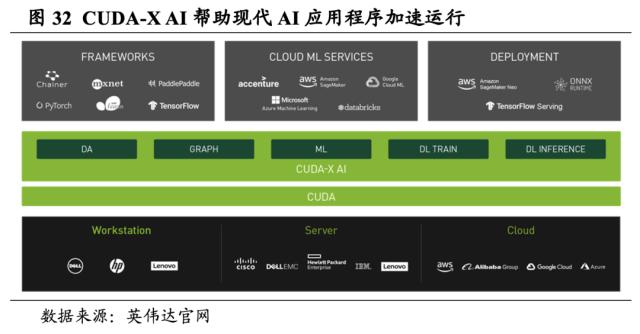
CUDA打造高兼容性的GPU通用平台,推动GPU应用场景持续扩展。CUDA可以充当英伟达各GPU系列的通用平台,因此开发者可以跨GPU配置部署并扩展应用。CUDA最初用于辅助GeForce提升游戏开发效率,但随着CUDA的高兼容性优势彰显,英伟达将GPU的应用领域拓展至计算科学和深度学习领域。因此,通过 CUDA 开发的数千个应用目前已部署到嵌入式系统、工作站、数据中心和云中的GPU。同时,CUDA打造了开发者社区,提供开发者自由分享经验的途径,并提供大量代码库资源。我们认为,目前CUDA已形成极高的准入壁垒,也成为了英伟达持续扩展人工智能领域市场的品牌影响力来源。
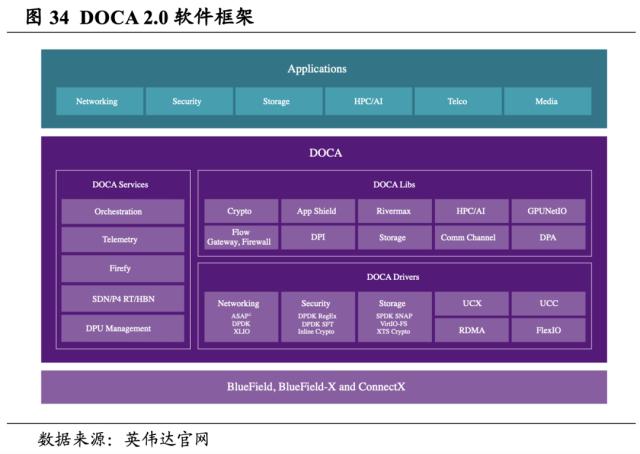
DOCA与DPU结合打造开发平台,成为激发DPU潜力的关键。借助DOCA,开发者可通过创建软件定义、云原生、DPU 加速的服务来对未来的数据中心基础设施进行编程。具体而言,DOCA 软件由软件开发套件(SDK)和运行时(Runtime)环境组成,SDK中包含了系统的软件框架,Runtime则包括用于在整个数据中心的成百上千个DPU上配置、部署和编排容器化服务的工具。DOCA与DPU的结合能够开发具备突破性的网络、安全和存储性能的应用,有效满足现代数据中心日益增长的性能和安全需求。
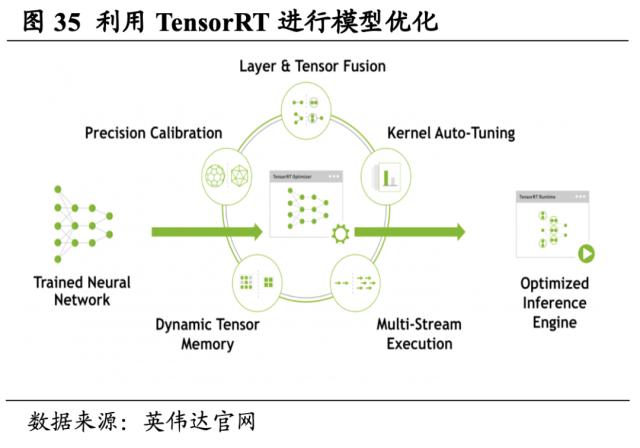
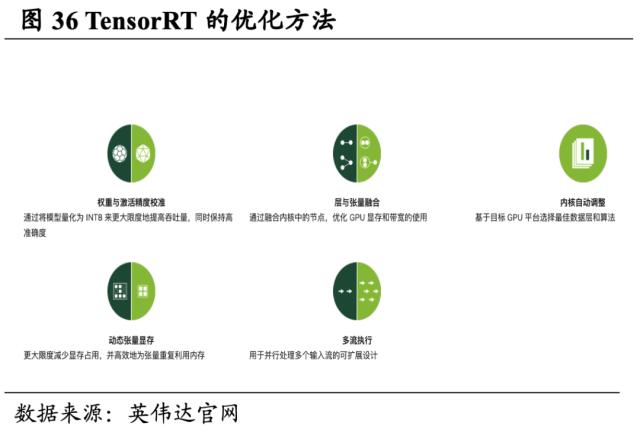
打造深度学习推理优化器TensorRT,显著提高了GPU 上的深度学习推理性能。TensorRT是英伟达一款高性能推理平台,此SDK包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高吞吐量。与仅使用CPU的平台相比,TensorRT可使吞吐量提升高达40倍。借助 TensorRT,开发者可以在所有主要框架中优化训练的神经网络模型,提升模型激活精度校准,并最终将模型部署到超大规模数据中心、嵌入式或汽车产品平台中。
TensorRT以CUDA为基础构建,同时与开发框架紧密集成。TensorRT以 CUDA 为基础,可帮助开发者利用 CUDA-X 中的库、开发工具和技术,针对人工智能、自主机器、高性能计算和图形优化所有深度学习框架中的推理。通过TensorRT的使用,可以对训练的神经网络模型进行INT8和FP16优化,例如视频流式传输、语音识别、推荐算法和自然语言处理,并将优化后的模型部署至应用平台。同时TensorRT也与Tensorflow、MATLAB的深度学习框架集成,可以将预训练的模型导入至TensorRT进行推理,具备较高的兼容性。
2.3.应用框架构筑封装SDK,打造标准行业场景
SDK助力标准行业场景搭建,大幅提升开发效率和性能。SDK全称Software Development Kit,指为特定的硬件平台、软件框架、操作系统等建立应用程序时所使用的开发工具的集合。英伟达基于自身丰富的“软件+硬件”一体化优势,将其进行优化并封装为SDK,形成了自身完备的应用框架体系,为行业中突出问题的解决打造了标准行业场景。完备的SDK体系有助于更大程度提高开发者的工作效率,相关应用框架的性能和可移植性也将因此得到显著提升。
2.3.1. 元宇宙应用-Omniverse
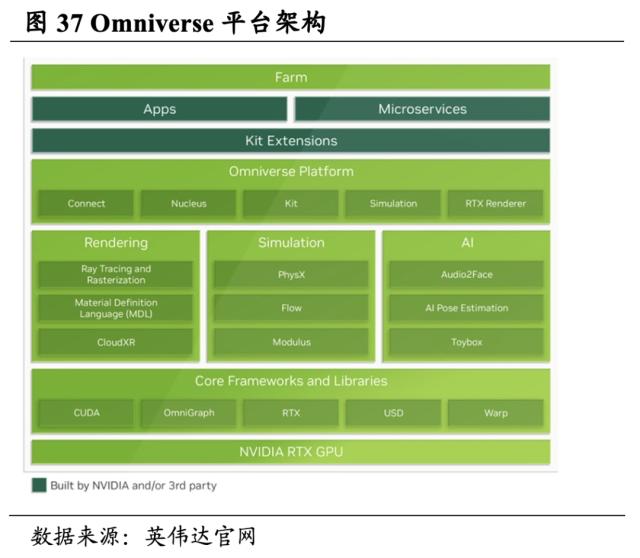
开创元宇宙模拟平台Omniverse,共同设计运行虚拟世界和数字孪生。Omniverse是一个基于USD(Universal Scene Description)的可扩展平台,在Omniverse中,艺术家可以使用3D工具创作具备全设计保真度的实时虚拟世界,企业可以通过数字孪生模型在产品投产前实时设计、仿真和优化他们的产品、设备或流程。目前,Omniverse拥有15万余名个人用户和300余家企业用户。此外,英伟达也推出了LaaS产品 Omniverse Cloud,可连接在云端、边缘设备或本地运行的Omniverse应用,实现在任何位置设计、发布和体验元宇宙应用,例如,借助Omniverse Cloud Simple Share服务,只需单击即可在线打包和共享Omniverse场景。
2.3.2. 云端AI视频流-Maxine
Maxine提供GPU加速的AI SDK和云原生服务,可用于部署实时增强音频、视频和增强现实效果的AI功能。Maxine使用最先进的模型创造出可以使用标准麦克风和摄像头设备实现的高质量效果。其中,Audio Effects SDK提供基于AI的音频质量增强算法,提高窄带、宽带和超宽带音频的端到端对话质量,包括提供去噪、回声消除、音频超分辨率等效果,而Video Effects SDK提供虚拟背景、放大器、减少伪影和眼神接触等AI的GPU加速视频效果。Maxine可以部署在本地、云端或边缘,微服务也可以在应用程序中独立管理和部署,从而加快开发时间。

2.3.3. 语音AI-Riva
Riva构建定制实时语音AI应用,形成端到端语音工作流程。随着基于语音的应用在全球的需求激增,这要求了语音AI应用需识别行业特定术语,并跨多种语言作出自然的实时响应。Riva包含先进的实时自动语音识别(ASR)和文字转语音 (TTS)功能。用户可选择预训练的语音模型,在自定义数据集中使用 TAO工具套件对模型进行微调,能将特定领域模型的开发速度提升10倍。Riva的高性能推理依赖于TensorRT,并已完全容器化,可以轻松扩展到数千个并行流。
2.3.4. 数据分析-RAPIDS
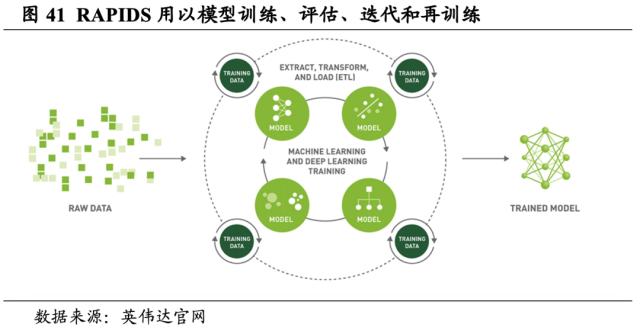
RAPIDS为全新高性能数据科学生态系统奠定了基础,并通过互操作性降低了新库的准入门槛。英伟达打造了由一系列开源软件库和API组成的PAPIDS系统,支持从数据读取和预处理、模型训练直到可视化的全数据科学工作流程。通过集成领先的数据科学框架(如Apache Spark、cuPY、Dask和Numba)以及众多深度学习框架(如PyTorch、TensorFlow 和Apache MxNet),RAPIDS可帮助扩大采用范围并支持集成其他内容。整体而言,RAPIDS以CUDA-X AI为基础,融合了英伟达在显卡、机器学习、深度学习、高性能计算(HPC)等领域多年来的发展成果。
2.3.5. 医疗健康-Clara
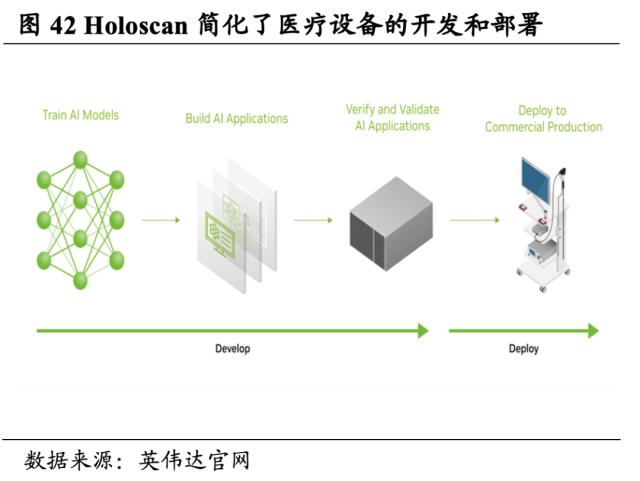
打造AI助力的医疗健康平台Clara,助力新一代医疗设备和生物医学研究。Clara主要包含Holoscan、Parabricks、Discovery和Guaradian四大应用,分别用于医疗影像和医疗设备、基因组学、生物制药和智慧医院建设。以Holoscan为例,开发者可以构建设备并将AI应用直接部署到临床环境中,使用准确的数字孪生模拟手术环境有助于提高手术效率并缩短患者留在手术室内的时间。其中,MONAI是专用的开源医疗AI 框架,目标是通过构建一个强大的软件框架来加快创新和临床转化的步伐。
2.3.6. 高性能计算
HPC软件开发套件助力高性能计算。HPC SDK C、C++和 Fortran编译器支持使用标准C++和Fortran、OpenACC指令和CUDA 对 HPC建模和模拟应用程序进行GPU加速。GPU加速的数学库提高了常见HPC算法的性能,而优化的通信库支持基于标准的多GPU和可扩展系统编程。性能分析和调试工具可简化HPC应用程序的移植和优化,而容器化工具可在本地或云端轻松部署。
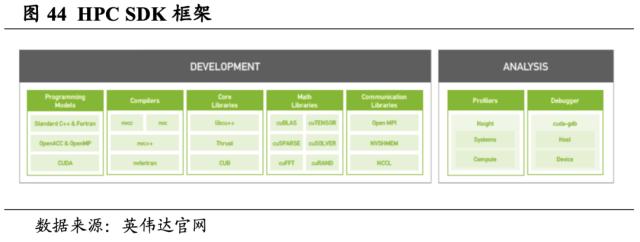
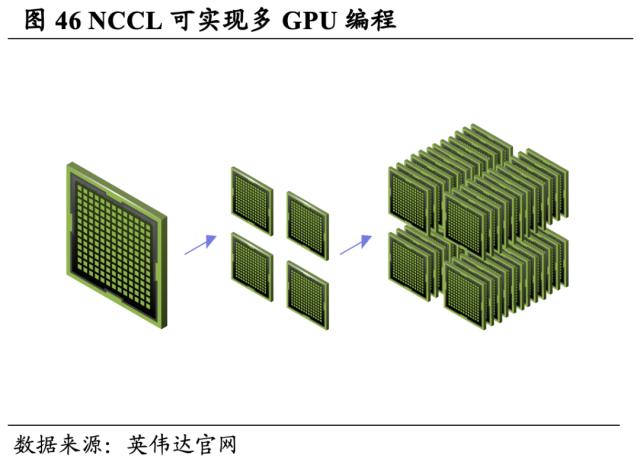
HPC SDK的主要功能包括GPU数学库、Tensor Core优化、CPU优化、多GPU编程、可拓展系统编程、Nsight性能分析等。其中,GPU 加速的数学库适用于计算密集型应用,cuBLAS和cuSOLVER 库可提供来自LAPACK的各种BLAS例程以及核心例程的多GPU的实施,并尽可能自动使用GPU Tensor Core。集合通信库 (NCCL) 能够实现多GPU编程,使用MPI兼容的all-gather、all-reduce、broadcast、reduce和reduce-scatter例程实现高度优化的多GPU和多节点集合通信基元,以利用HPC服务器节点内和跨HPC服务器节点的所有可用GPU。

2.3.7. 智能视频分析-Metropolis
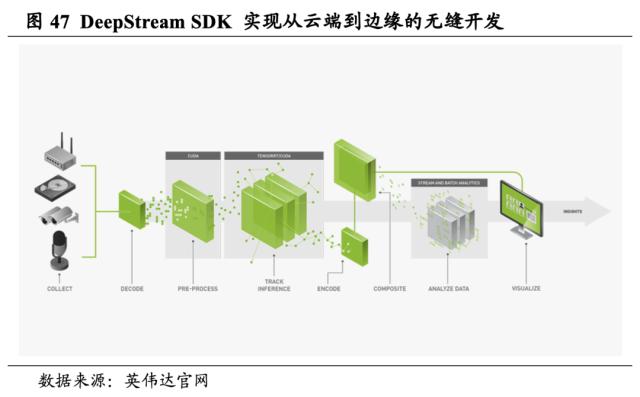
Metropolics将像素转化为见解,致力打造全方位智能视频分析应用框架。Metropolics将可视化数据和AI整合,处理数万亿传感器生成的海量数据,提高众多行业的运营效率和安全性,企业可以创建、部署和扩展从边缘到云端的AI和物联网应用。DeepStream SDK是由AI驱动的实时视频分析SDK,可以显著提高性能和吞吐量;TAO 工具包借助计算机视觉特定的预训练模型和功能,加速深度学习训练;TensorRT将高性能计算机视觉推理应用程序从Jetson Nano部署到边缘的T4服务器上。目前,Metropolics已广泛用于智慧城市建设、零售物流、医疗健康、工业和制造业等。
2.3.8. 推荐系统-Merlin
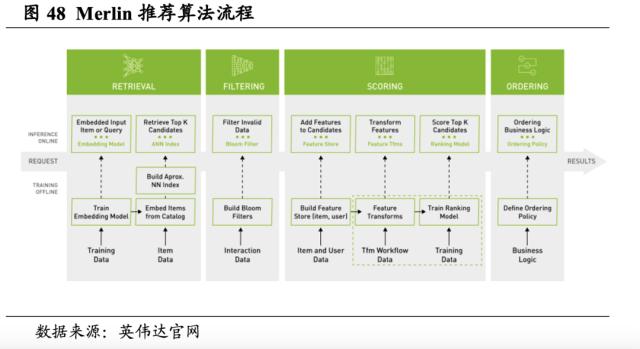
英伟达提供用于大规模构建高性能推荐系统的开源框架Merlin。Merlin使数据科学家、机器学习工程师和其他研究人员能够大规模构建高性能的推荐器。Merlin框架包括库、方法和工具,通过实现常见的预处理、特征工程、训练、推理和生产部署,简化了推荐算法的构建。Merlin 组件和功能经过优化,可支持数百TB数据的检索、过滤、评分和排序,并可以通过易于使用的API访问。
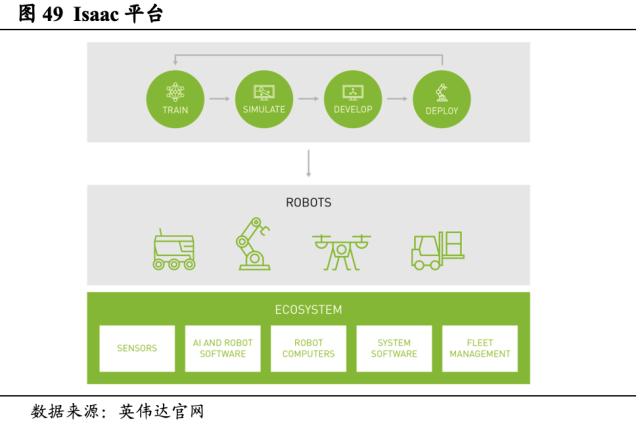
2.3.9. 机器人-Isaac
从开发、仿真到部署,Isaac平台加速并优化机器人开发。工业和商用机器人的开发过程相当复杂,在许多场景中,缺乏结构化的环境为开发提供支持。Isaac机器人开发平台为解决这些挑战,打造了端到端解决方案可帮助降低成本、简化开发流程并加速产品上市。其中,本地和云端提供的Isaac Sim能够创建精准的逼真环境,为机器人产品提供仿真测试环境;EGX Fleet Command 和Isaac for AMR (包括 Metropolis、CuOpt 和DeepMap)能够管理机器人编队以进行部署。
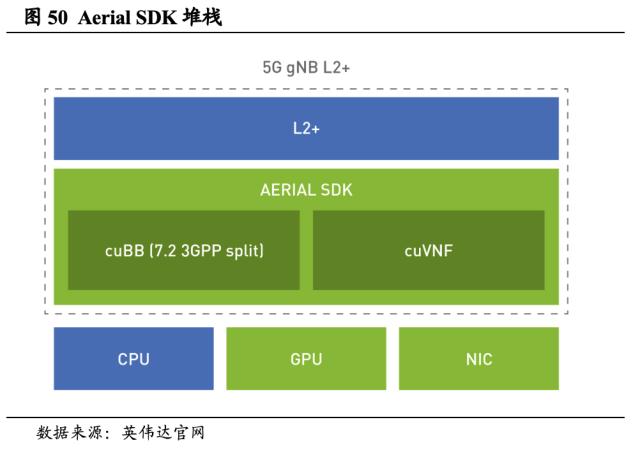
2.3.10. 电信-Aerial
Aerial是用于构建高性能、软件定义、云原生的5G应用框架。Aerial旨在构建和部署GPU加速的5G虚拟无线接入网。Aerial SDK是一个可高度编程的物理层,能够支持L2及以上的函数,借助GPU加速,复杂计算的运行速度超过现有的L1处理解决方案。Aerial SDK支持CUDA Baseband(cuBB)和CUDA虚拟网络函数(cuVNF),将构建可编程且可扩展的软件定义5G无线接入网的过程变得更为简单。
2.4. 行业解决方案全覆盖,助推行业生态迭代
2.4.1. 人工智能与机器学习技术
AI Foundations打造面向企业的生成式AI,MaaS(模型即服务)帮助企业开发自己的人工智能模型。英伟达AI Foundations是专为AI打造的行业解决方案。如今,生成式AI正在扩展到全球的企业中,黄仁勋指出,AI Enterprise将如Red Hat之于Linux一般,为英伟达的所有库提供维护和管理服务,未来它还被整合至全球范围的机器学习操作渠道内。整体而言,英伟达正在通过一系列云服务套件、预训练的基础模型、尖端框架、优化推理引擎,和API一同为生成式AI提供支持。AI Foundations通过搭载在DGX Cloud - AI 超级计算机上的NeMo、Picasso和 BioNeMo云服务发挥潜能,可以提供文本生成、图像生成、聊天机器人、总结和翻译等生成式AI开发服务。

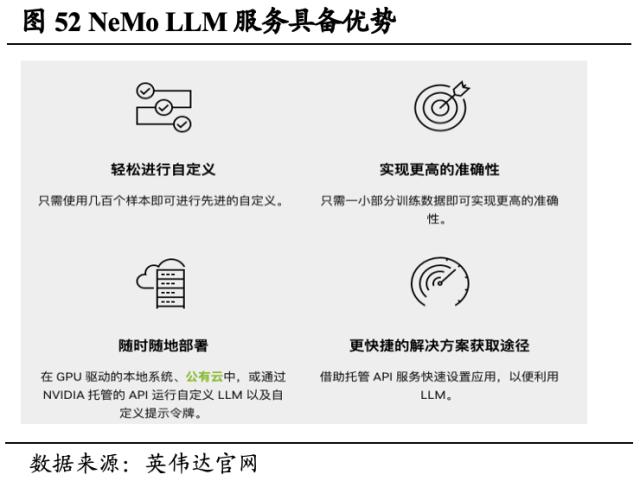
提供NeMo LLM服务,致力大型语言模型的开发与维护。英伟达NeMo LLM服务令用户可以自定义和使用在多个框架上训练的LLM,并可在云上使用NeMo LLM服务部署企业级AI应用。NeMo LLM降低了大模型开发与维护的难度,实现了文本生成、摘要、图像生成、聊天机器人、编码和翻译等功能。同时NeMo LLM将Megatron 530B 模型作为一款云API公开,作为一种端到端框架,Megatron 530B可用于部署最高数万亿参数的LLM。
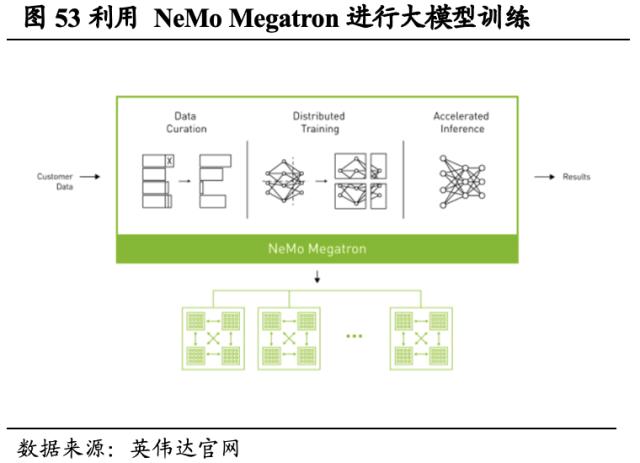
加速机器学习训练时间,打造高性能的数据科学解决方案。除上述的Maas外,英伟达也为AI提供训练和推理的计算机平台。从机器学习角度,英伟达借助高速 GPU 计算运行整个数据科学工作流程。APIDS应用框架的使用令原本需要花费几天的流程现在只需几分钟即可完成,因此用户可以更加轻松、快速地构建和部署价值生成模型。基于英伟达的解决方案,仅使用约16台DGX A100即可达到350台基于CPU的服务器的性能。减少机器学习中的由于算力限制而被迫产生的缩减取样、限制模型迭代次数等对企业实际业务决策产生的负面影响,加速模型投入生产的周期。
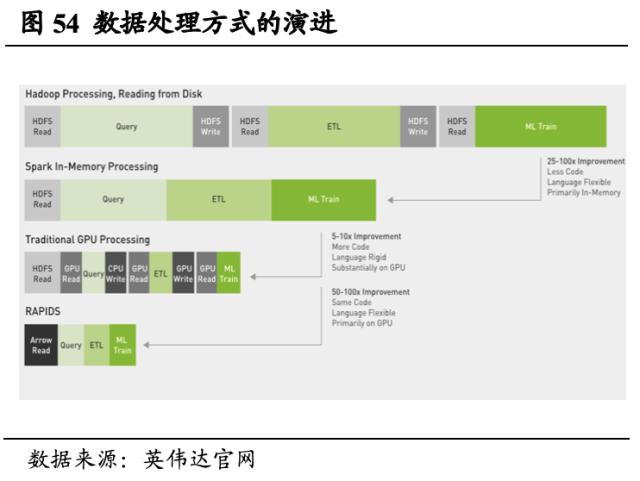

打造完整深度学习训练和深度学习推理平台,持续扩大深度学习领导地位。深度学习领域,从训练平台角度,用户可选择本地工作站、数据中心、云端作为训练平台,借助SDK中的软件和框架库进行深度学习训练,也可从英伟达GPU Cloud免费访问所有所需的深度学习训练软件。从推理平台角度,用户可借助TensorRT平台以及Triton推理服务器进行模型推理和部署,Triton服务器允许团队通过TensorFlow、PyTorch、TensorRT Plan、Caffe、MXNet 或其他自定义框架,在任何基于GPU或 CPU的基础设施上,从本地存储、Google云端平台或AWS S3部署经训练的模型。
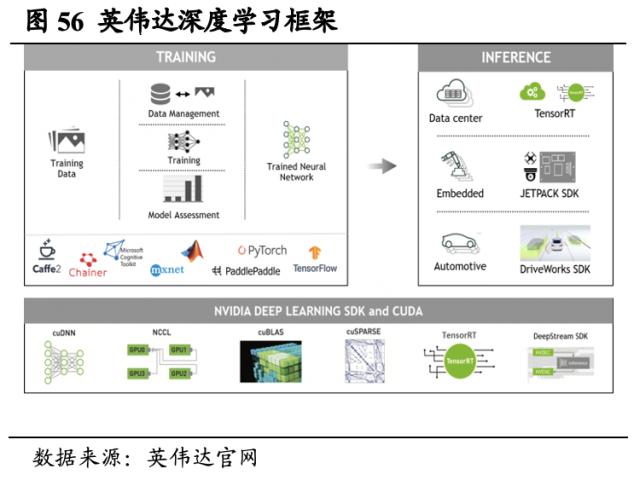
AI Enterprise 提供AI 工作流解决方案。AI Enterprise是英伟达打造的端到端的云原生AI软件套件,它可以加速数据科学流程,简化预测性AI模型的开发和部署。AI Enterprise 将AI框架、预训练模型和各种资源(例如Helm图表、Jupyter Notebook和文档)封装组合,可缩短开发时间、降低成本、提高准确性和性能。
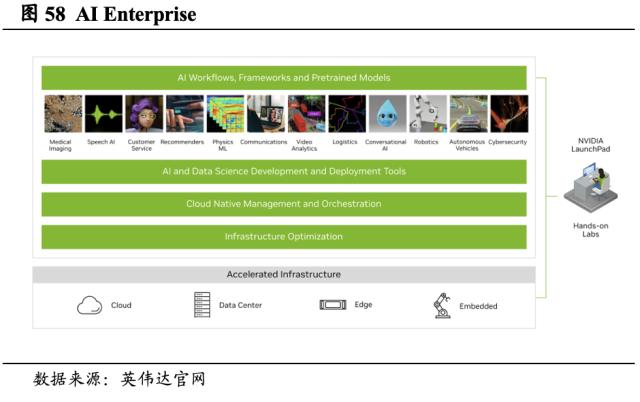
2.4.2. 数据中心与云计算解决方案
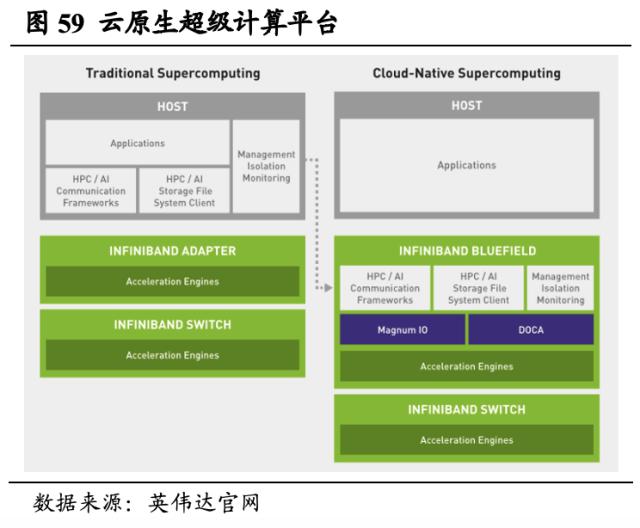
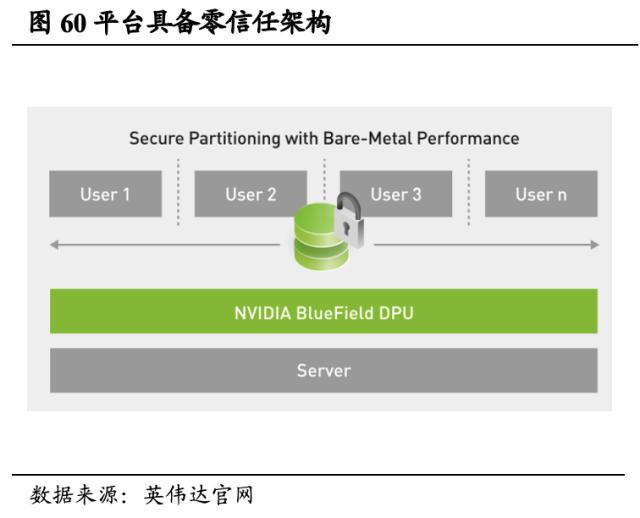
云计算解决方案优势充分释放,为全球创新者提供巨大算力。英伟达的云合作伙伴包括阿里云、谷歌云、腾讯云、AWS、IBM Cloud和Microsoft Azure等,用户可以通过云合作伙伴使用英伟达服务。此外,英伟达基于BlueField DPU架构和Quantum InfiniBand网络搭建了云原生超级计算平台。DPU能够为主机处理器卸载和管理数据中心基础设施,实现超级计算机的安全与编排;并且云原生超级计算机实现在多租户环境中的零信任架构,最大程度保障了安全性。同时,英伟达也具备强大的边缘计算服务,形成“云计算+边缘计算”的服务体系。
cuLitho计算光刻技术软件库引入加速计算,加速半导体行业芯片设计和制造速度。英伟达cuLitho的推出以及与半导体行业领导者TSMC、ASML和Synopsys的合作,使晶圆厂能够提高产量、减少碳足迹并为2纳米及更高工艺奠定基础。cuLitho在GPU上运行,其性能比当前光刻技术工艺提高了40倍,能够为目前每年消耗数百亿CPU小时的大规模计算工作负载提供加速,仅需500个DGX H100系统即可完成原本需要4万个CPU系统才能完成的工作。在短期内,使用cuLitho的晶圆厂每天的光掩模(芯片设计模板)产量可增加3-5倍,而耗电量可以比当前配置降低9倍。
2.4.3. 汽车行业解决方案
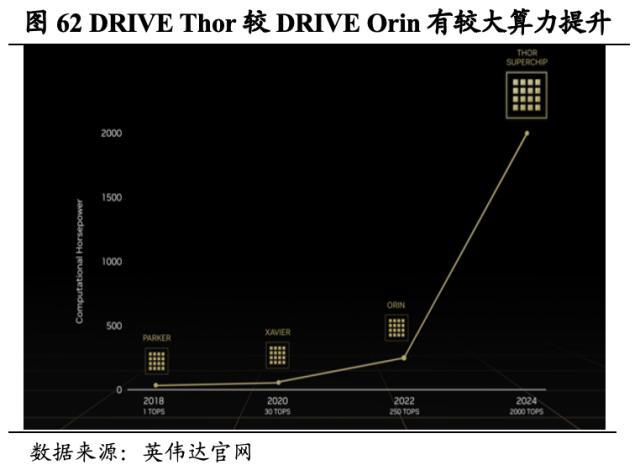
英伟达自研NVIDIA DRIVE,形成适合自动驾驶汽车的硬件+软件+架构有机统一。硬件端,DRIVE Hyperion是用于量产自动驾驶汽车的平台,具备用于自动驾驶的完整软件栈,以及驾驶员监控和可视化功能。DRIVE Hyperion搭载DRIVE Orin SoC(系统级芯片),可提供每秒254万亿次运算的算力负荷。同时,英伟达2022年9月借助最新GPU和CPU打造了新一代SoC芯片DRIVE Thor,其可提供2000 万亿次浮点运算性能,计划2025年DRIVE Thor能够得到量产。

DRIVE SDK令开发者高效部署自动驾驶应用程序成为可能,造就未来出行体验。DRIVE SDK为开发者提供适应自动驾驶的构建块和算法堆栈,开发者可以构建和部署包括感知、定位、驾驶员控制和自然语言处理的一系列应用程序。


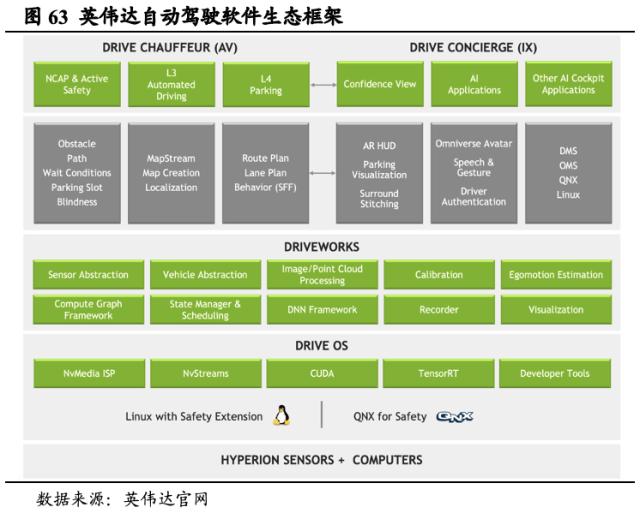
DRIVE基础架构包括开发自动驾驶技术全流程所需的数据中心硬件、软件和工作流。英伟达提供高效节能的AI计算加速训练,有助于AI收集大量真实行驶数据作为训练集;在DRIVE Sim中,可以通过模拟驾驶在虚拟世界中进行测试,得到各种罕见和危险驾驶情形下的驾驶数据。目前,英伟达开发的AI赋能自动驾驶汽车已经应用至各大主流汽车制造商,成为自动驾驶汽车开发的首要工具。

2.4.4. VR与游戏产业产品
英伟达GPU为VR头盔和GeForce Game Ready驱动提供即插即用的兼容性。VR成像是否连贯将极大影响头显的使用体验,舒适的VR体验要求显示器有效分辨率至少为4K且最低刷新率为90Hz,这就需要GPU为其提供支持。GeForce RTX GPU兼容目前市场上主流VR头盔,通用性较强。从性能上看,GeForce RTX GPU依托其DLSS、光线追踪和PhysX三大成像技术为用户模拟如真实世界般的VR体验。

全方位覆盖游戏娱乐体验,打造专业游戏环境。目前有超2亿游戏玩家和创作者使用GeForce GPU,针对这一客户群体,英伟达打造了一系列专业游戏服务: GeForce Experience可以截取并与好友分享截图、视频和直播;Game Ready 驱动程序可实现一键优化游戏设置;Broadcast App提供专业化直播服务,如只需点击一个按钮即可消除噪音或添加虚拟背景;Omniverse Machinima可以实现对虚拟世界中的角色及其环境进行操作处理并实现动画化
3
重新定义市场,助推AI发展
3.1. 长期稳居显卡市场龙头,市场份额保持高位
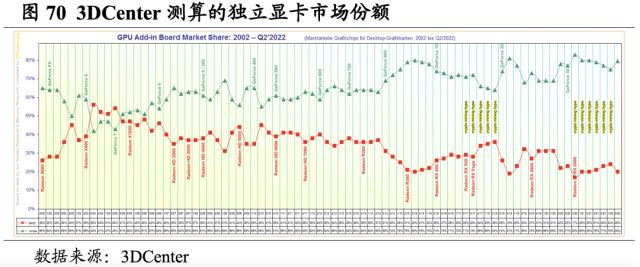
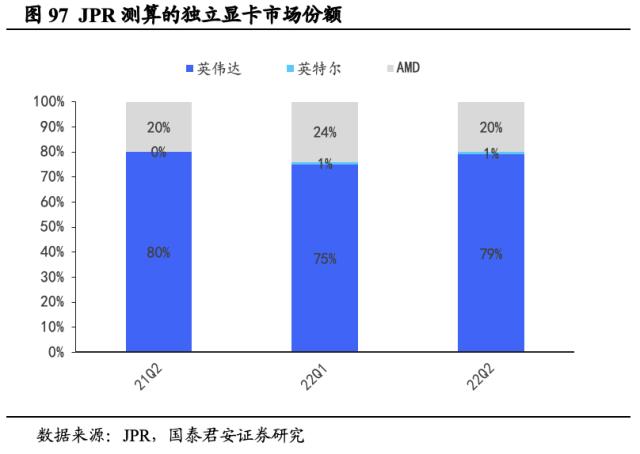
英伟达独显市场份额长期稳居高位,与AMD呈此消彼长关系。据3DCenter,2022Q2全球独立显卡共计出货约1040万张,总销售额约55亿美元,与2021年存在较大差距,其中显卡平均售价从2021Q2的1029美元大幅跌落至2022Q2的529美元。据JPR测算,22Q2英伟达出货占全球独立显卡市场份额79%,同比增长4pct,环比降低1pct。此外,AMD(超威半导体)囊括了20%的市场份额,作为新入局者英特尔(Intel),其市场份额仅1%,可见英伟达在独立显卡领域长期耕耘的市场优势显著,尤其是高端显卡市场。而后,22Q3全球独立显卡销量同降33.7%至690万张,22Q4同增7.8%至743万张。
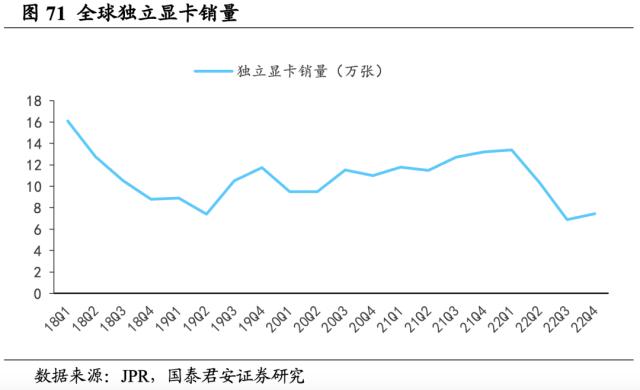
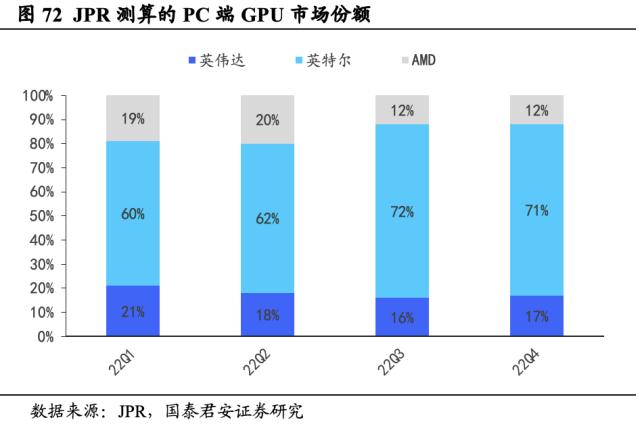
2022年全球GPU市场低迷,英特尔保持全球最大PC端GPU供应商地位。据JPR, 22Q4全球共出货6420万块独立GPU和集成GPU,同比-38%,环比-15.4%,整体降幅明显,彰显市场需求低迷情绪,尤其是集成显卡制造商采购意愿下滑严重。从市场份额角度,以22Q4为例,英特尔PC端GPU销售额占71%,英伟达和AMD分别占17%和12%。整体来看,集成显卡市场库存过剩和需求减弱的供需矛盾仍暂未缓解,出货量或将继续维持低位。
3.2. 合作伙伴网络庞大,AI市场持续开拓
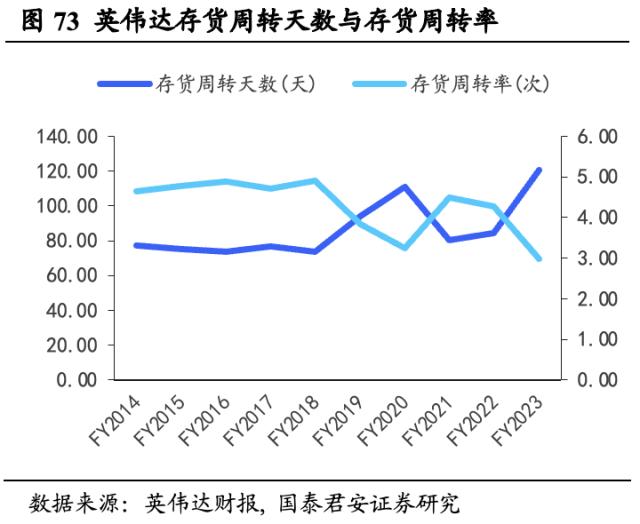
英伟达主要客户群体覆盖顶尖科技公司,未来将持续向人工智能市场开拓。英伟达处半导体产业链上游研发设计环节,半导体细分领域几大头部厂商垄断力较强,其主要客户包括华硕、联想、惠普、Facebook、IBM、慧与、三星等。下游需求严重影响英伟达的存货与生产计划,从存货角度分析,FY2020存货周转天数上涨主要由原材料价格上涨提前追加采购所致,FY2023存货周转天数再度高涨则由于需求疲软造成的库存积压。但随着AI算力需求提高重振英伟达销售预期,我们认为英伟达存货周转有望重返合理区间,同时其AI研发的持续投入也将有望吸引更多AI公司使用英伟达芯片产品。
英伟达基于庞大合作伙伴网络,共同推动视觉计算未来。英伟达作为行业领导者,率先推出了视觉计算解决方案,并在近30年来通过合作伙伴网络(NPN)将产品投入市场。合作伙伴包括增值经销商、解决方案集成、设计或制造系统、托管服务、咨询以及为英伟达产品和解决方案提供维护服务的公司。同时,英伟达积极通过GTC大会吸引更多的全球合作伙伴,2023年GTC大会钻石合作商就包括微软、谷歌云、阿里云、戴尔科技等国内外大厂,黄仁勋指出,目前全球英伟达生态已有400万名开发者、4万家公司和英伟达初创加速计划中的1.4万家初创企业。


3.3. AI市场持续高增,周期布局价值彰显
AI芯片市场成为新的增长极,周期布局价值渐显。云计算、人工智能、工业5G和加速计算等业务增长将成为解决计算时代症结的最后几块拼图。硬件+软件的完整生态系统将有助英伟达在AI的极速发展中稳定其头部供应商地位。据IDTechEx发布的报告《人工智能芯片2023-2033》预测,到2033年,全球AI芯片市场将增长至2576亿美元。JPR也曾预测,2022-2026年全球GPU销量复合增速将保持在6.3%水平,2027年全球GPU市场规模有望超320亿美元。目前Open AI模型主要由英伟达GPU进行训练,我们看好AI芯片市场激增对英伟达投资价值的催化作用。
英伟达预测自身总潜在市场为万亿美元量级,对各业务线持整体乐观预期。在2022年3月投资者的活动中,英伟达指出其业务领域的总潜在市场 (TAM) 为 1 万亿美元,其中游戏业务约1000亿美元,人工智能企业软件1500亿美元,Omniverse业务1500亿美元,硬件与系统3000亿美元,以及自动驾驶业务市场3000亿美元。即便英伟达并未清晰给出其计划实现这一目标的具体时间,但仍从一定程度上反映了英伟达对其各业务条线市场份额权重的合理预期。

3.4. 重塑摩尔定律,AI iPhone时刻提供新机遇
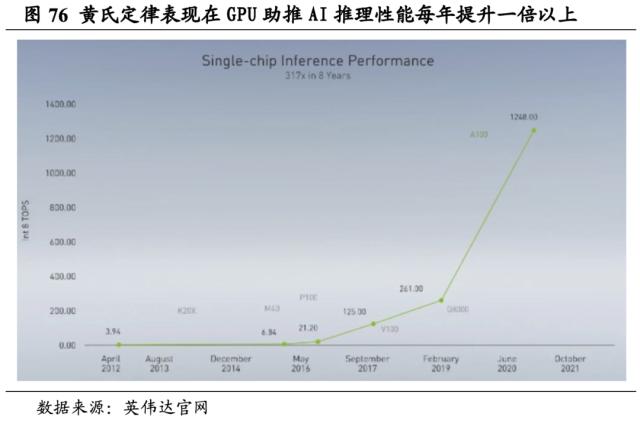
摩尔定律逐渐失效,“黄氏定律”重塑行业生态正当时。摩尔定律指在价格不变的前提下,集成电路上可容纳的晶体管的数目,约每隔约18个月便会增加一倍,半世纪以来,摩尔定律指引着芯片市场迈向繁荣。但随着传统半导体晶体管结构已进入纳米级别,摩尔定律也逐渐在高成本的驱动下逐渐失效。但如今,大模型对于算力激增的需求已远大于摩尔定律所预估。黄仁勋对AI性能的提升作出预测,指出GPU将推动AI性能实现每1年翻1倍,也就是每10年GPU性能将增长超1000倍。这一论断也被称之为“黄氏定律”。英伟达首席科学家兼研究院副总裁Bill Dally表示,目前单芯片推理性能的提升主要原因在于Tensor Core的改进、更优化的电路设计和架构,而非制程技术的进步。因此,在摩尔定律消失之后,黄氏定律将不断催生计算性能的进步。
ChatGPT成为AI的iPhone时刻。无论是率先发明GPU并保持约两年一次架构更新速度,亦或是成为首个打造硬件+软件生态的公司,英伟达都为行业生态系统创造了新的发展机遇。而当下以ChatGPT为代表的人工智能对社会的影响正如当年Apple通过iPhone打开全球智能手机市场一般。而英伟达的远见即在于提前布局AI业务,早在2016年,英伟达就向OpenAI交付了英伟达DGX AI超级计算机,成为支持ChatGPT的大语言模型突破的引擎,可以说DGX超级计算器是现代“AI工厂”。

4
研发创新贯穿公司历史,迭代公司增长曲线
4.1. 研发投入持续高增,研发团队规模日益壮大
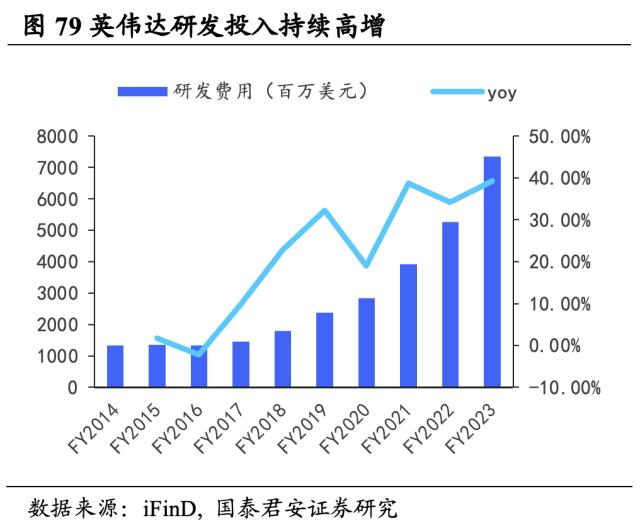
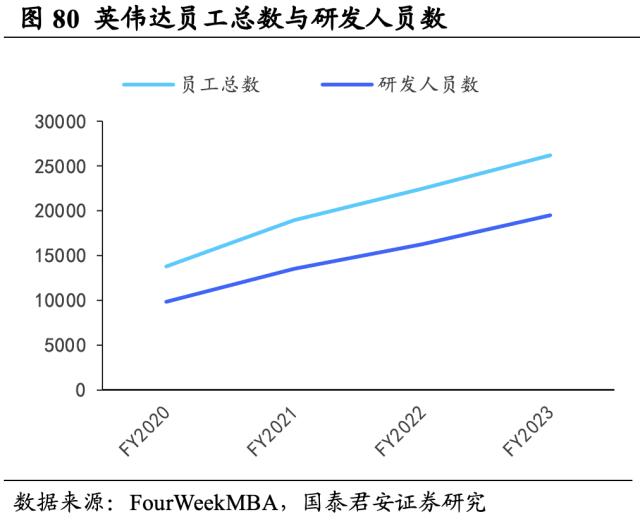
英伟达持续加大研发投入,注重创新能力培育。FY2023年英伟达研发费用达73.39亿美元,同增39.31%,近年来英伟达研发费用增速明显,在FY2021-FY2023已连续三年呈现超30%的同比增长率。据FourWeekMBA统计,截至2023年1月,英伟达全球员工总数共26196人,其中研发人员19532人,研发人员占比约75%。四年间英伟达研发人员数量近乎翻倍,研发人员的高占比反应了公司对于研发创新这一企业生命线的重视。
4.2. AI拐点时刻,大型语言模型形成新技术重心
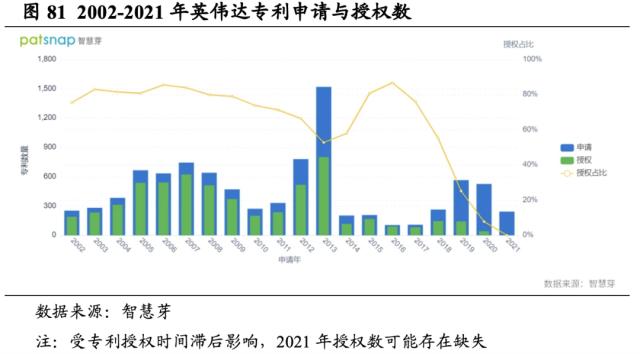
专利申请数处行业前列,神经网络领域成为研究和专利申请重心。据智慧芽数据,截止2021年,英伟达及其关联公司共计申请超9700件专利,集中在GPU相关硬件领域。其中2013年达到专利申请与授权最高值。自2014年起专利申请与授权较前值显著降低,授权占比亦呈现下滑趋势。出现这种转变的原因主要在于研发重心转移带来的产出成果更迭。对比1993-2013年和2014-2021年专利关键词云,“处理器“、”存储器“、“计算机程序单元”的比重相对降低,取而代之的首位关键词为“神经网络”,反映了神经网络相关技术成为英伟达研发的首要方向。

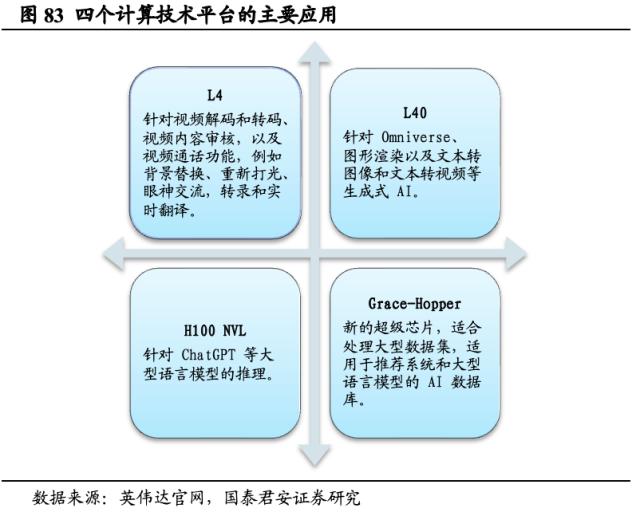
大型语言模型业务成为未来技术发展重心,发布四大新计算技术平台。在GTC 2023上,英伟达加快生成式AI应用的部署,推出四个计算技术平台,分别是用于AI视频的英伟达L4,针对Omniverse、图形渲染以及文本转图像和文本转视频等生成式AI的英伟达L40,用于大型语言模型推理的H100 NVL以及适用于推荐系统和大型语言模型数据库的Grace Hopper。黄仁勋表示:“AI 正处于一个拐点,为每个行业的广泛采用做准备。从初创企业到大型企业,我们看到人们对生成式 AI 的多功能性和能力越来越感兴趣。”而大型语言模型业务也将因此成为英伟达技术发展的重心。

4.3. 区位优势突出,持续强化产学研深度合作
英伟达充分利用硅谷的区位优势,与学术界保持着长期的合作关系,提供不竭的创新动力。英伟达除了与专业的研究团队开展合作外,也将顶尖高校的优秀毕业生作为重点人才储备,持续强化产学研深度合作。主要合作学术研究项目包括与加州大学伯克利分校的ASPIRE项目、与北卡罗来纳州立大学等多所高校联合的CAEML项目和CV2R项目、以及与斯坦福工程学院的SCIEN项目等,涵盖机器学习、虚拟现实等领域,覆盖软硬件市场。
5
打造多元文化,勇担社会责任
5.1. 坚持可持续发展,践行ESG目标
英伟达注重可再生能源与生产效率,助力践行ESG目标。英伟达在每年度均计划购买或生产大量的可再生能源,以全面满足全球对电力的使用需求。此外,英伟达的GPU通过算力提升降低了能源消耗,其生产的GPU对于某些AI和HPC工作负载,其能效通常比CPU高20倍。2022年5月,英伟达推出液冷GPU,据Equinix和英伟达单独测试,采用液冷技术的数据中心工作负载可与风冷设施持平,同时消耗的能源减少约30%。值得一提的是,Green500排行是衡量超级计算机的能效的重要指标,在2022年6月的Green500榜单里排名前30的超级计算机中,有23台由英伟达的GPU提供支持。

5.2. 承担社会责任,投身公益活动
员工致力于构建推动人类进步的技术,并为其工作和生活的社区提供支持。英伟达表示,作为积极承担社会责任的优秀公司,他们的员工古道热肠,向全球数百家慈善组织提供捐助。同时英伟达建立了专项基金会,37%的员工在FY2023参与了基金会Inspire 365计划,共计捐赠超880万美元,提供了约29000小时的志愿服务时间,较FY2022同增 74%。加上以公司名义的捐赠,总捐赠额共计2250万美元,覆盖了55 个国家或地区的5800多家非营利组织。

5.3. 强调以人为本,深耕企业文化
英伟达注重打造多元企业文化,提升员工福祉。Glassdoor的评选结果显示,英伟达的员工将公司评为全美排名第1的工作场所。《财富》杂志亦将其评为“最佳雇主100强”。并且,英伟达致力于创造更加多元化的文化,构建“残障平等指数”、“企业平等性指数”和“性别平等指数”等指标,彰显企业以员工为本的理念,提供包容性的工作场所,并始终坚持履行其对同工同酬的承诺。
5.4. 关注客户隐私,持续提升产品安全
注重AI时代下数据安全问题,建立专业风险响应团队。英伟达打造了全球产品安全事件响应团队(PSIRT),通过及时的信息传递处理产品和服务相关的安全漏洞,并将NIST网络安全框架的元素和控件集成到其安全程序中。同时参与MITRE这一全球网络安全组织,扩展AI的 MITRE ATT&;CK框架,以更好响应AI时代新的威胁。
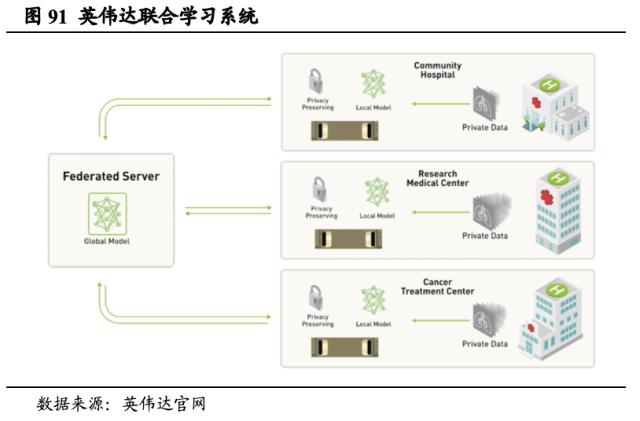
打造注重隐私保护的联合学习系统,产品安全整体可控。以医疗行业为例,英伟达推出的医学影像分析的联合学习系统( Federated Learning),可以通过构建全局模型避免患者的信息被无条件共享。医院、研究中心和疾控中心能够各自根据其既有数据于本地训练模型,并间隔一定时间将数据提交给全局参数服务器,该服务器可以通过整合各节点模型信息并生成新的模型,最后将模型重新反馈回各节点。该系统在隐私保护基础上最大程度保障了模型性能,合理利用了各方数据信息。
6
以超异构创新重塑大规模AI计算,
发动世界AI引擎
6.1. CPU难以支撑AI算力需求,市场亟需更强算力
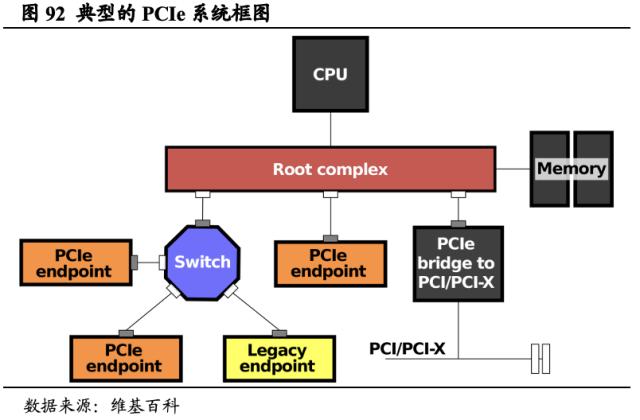
CPU主要以串行计算,基于CPU和PCIe的数据中心吞吐量严重不足。串行计算指的是多个程序在同一个处理器上被执行,只有在当前的程序执行结束后,下一个程序才能开始执行,CPU的运行主要以串行计算的方式进行。同时,据CSDN,以PCIe最新版本5.0为例,其传输速率仅有32 GT/s或25GT/s,PCIe吞吐量的计算方法为:吞吐量=传输速率*编码方案,因此传输速率的不足直接导致了CPU基于PCIe的吞吐量较小,也就意味着其带宽较小。并且,在此过程中CPU产生的功耗和延时均较高,会产生较高的计算成本。因此,基于CPU串行计算的特点和较小的带宽,已无法适应如今数据中心的算力要求。
CPU无法适应深度学习高并发、并行计算和矩阵处理等算力要求。以神经网络模型为例,其包含输入层、输出层和中间层(亦称隐藏层)。近年来,深度学习应用需求的激增倒逼开发者实现更强的函数模拟能力,这需要通过提升模型的复杂度来实现,这直接导致神经网络中间层数量的大增,最终使得神经网络参数数量的飙升。由于神经网络是高度并行的,使用神经网络做的许多计算都需要分解成更小的计算,尤其是利用卷积神经网络进行图像识别时,卷积和池化等过程需进行大量矩阵运算,而CPU内部计算单元有限,在执行此类任务时将极大的消耗模型训练的时间。基于多层神经网络的复杂运算亟需更强算力的现实需求。
6.2. GPU生逢其时,英伟达异军突起
6.2.1. 技术日新月异,AI芯片应时代需求而生
GPU解决算力限制顽疾,高带宽适应模型训练需要。与CPU相比,使用GPU进行大规模并行计算的优势得到了充分彰显,以H100 Tensor Core GPU为例,其支持多达18个NVLink连接,总吞吐量为900 GB/s,是PCIe 5.0带宽的7倍,进而实现超快速的深度学习训练。对于神经网络模型的训练,GPU逻辑运算单元较多的优势能够得到充分的发挥,能够满足GPU无法实现的深度学习高并发、并行计算和矩阵处理的算力要求,因此GPU无疑成为了深度学习的硬件选择。
AI迭代飞速催生芯片技术创新,DPU、FPGA、ASIC等AI芯片应时代需求而生。AI时代呼唤新架构的产生,即便GPU相较CPU存在显著的算力优势,但市场可能需要比GPU性能更加优越的专用芯片,目前已并不仅只有GPU能适用以深度学习模型训练。近年来AI芯片技术爆发式增长,各类AI芯片上新迅速,我们参考《科学观察》杂志论文《AI芯片专利技术研发态势》,将AI芯片技术体系划分为如下11个分支领域。

ASIC适应定制化高需求使用场景,计算能力和效率可根据算法需要进行定制。专用集成电路(ASIC)指根据用户特定的要求和特定电子系统的需要而制造的集成电路,设计完成后集成电路的结构即固定。ASIC适用于对于芯片高需求且定制化程度较高的应用场景,如先前的矿机芯片和如今火热的自动驾驶芯片。Frost &; Sullivan数据统计,全球ASIC市场规模从2018年的299亿美元增长至2023年的674亿美元,复合增速达到17.7%。ASIC的发展有望一定程度上满足AI对算力激增的需求,但短期内难以打破英伟达GPU在市场份额的领先优势。
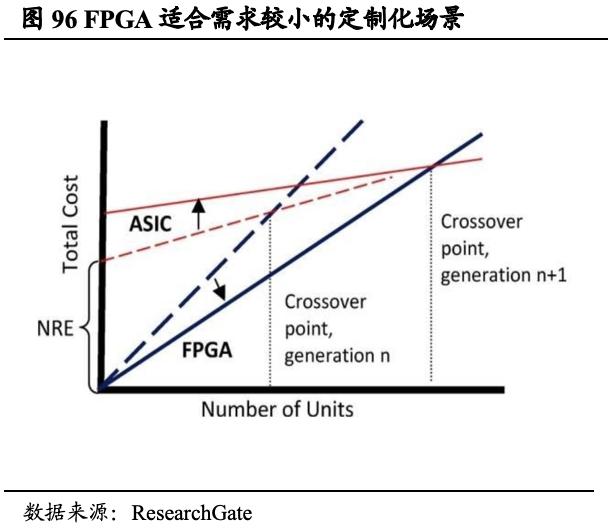
FPGA作为ASIC中半定制电路,“先购买再设计”,与AI相互成就。现场可编程门阵列(FPGA)指在硅片上预先设计,同时具有可编程特性的集成电路,开发者能够根据产品需求进行设计配置。相较原有的ASIC而言,FPGA具备了后期可编程性,适合需求量相对较小的定制化场景,具备更高的灵活性。FPGA技术目前具备较高的技术壁垒,但受益于AI技术持续扩展,行业需求具备明显确定性,将有望吸引更多竞争者入局,也将会对GPU的潜在市场产生冲击。
6.2.2. 激战AMD、英特尔及互联网巨头
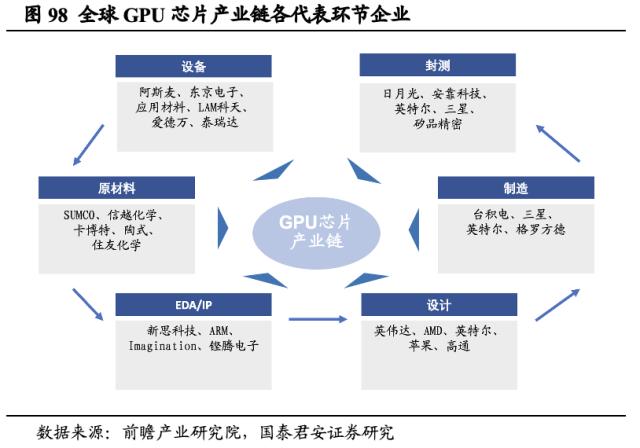
英伟达、英特尔、AMD为GPU领域行业巨头,苹果、高通等破局者不断涌入带来涟漪。据JPR测算,英伟达长期占全球独立显卡的市场份额近80%,其余市场份额几乎均被AMD抢占。因此GPU芯片市场英伟达和AMD共同主导。而英特尔为主要CPU制造商,同时也在PC端GPU具备领先份额。英伟达的主要竞争对手集中在GPU产业链的设计环节。但同时,苹果、高通等破局者也在进入GPU市场企图实现自研GPU以降低对外技术依赖的需求。
AMD是高性能与自适应计算领域的领先企业,处在半导体行业前沿。AMD作为英伟达在独立GPU领域的主要竞争对手,提供从处理器、显卡、软件和应用等全方位的产品服务,CPU+GPU+DPU+FPGA的产品线已全面布局。AMD在汽车、超级计算和高性能计算、网络电信、机器人领域自适应计算等也都提出了自己的全套解决方案。
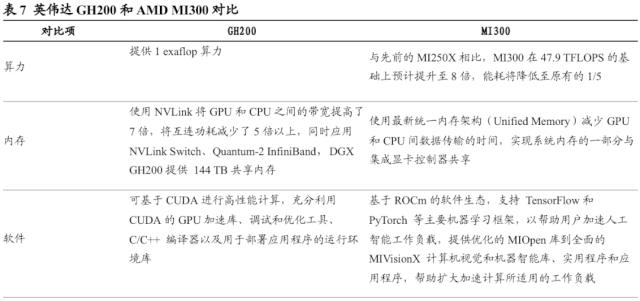
作为AMD最可能对标英伟达GH200的产品MI300年内将发布。Instinct MI300 具备开创新的适应数据中心设计,共包含13个小芯片,其中许多是 3D 堆叠的,以创建一个具有24个Zen 4 CPU内核并融合了CDNA 3 GPU和 128G HBM3显存的超级芯片,集成了 5nm 和 6nm IP。总体而言,该芯片拥有 1460 亿个晶体管,是 AMD 投入生产的最大芯片。我们认为,MI300不仅距离实现量产还有较长时间,且其算力相较于英伟达已量产的产品线依旧较低,与英伟达GPU研发和生产的整体差距约两年,目前对于英伟达GH200产生的竞争压力较小。

英特尔依托其在集成GPU市场的主导地位,提供具有卓越性能的图形解决方案。英特尔与英伟达和AMD不同,其在GPU领域更加专注集成显卡业务。英特尔的GPU家族包括锐炫显卡、锐炬Xe显卡和Data Center GPU等。英特尔研发了Xe-HPG 微架构,Xe-HPG GPU 中的每个 Xe 内核都配置了一组256位矢量引擎,可实现加速传统图形和计算工作负载,而新的1024位矩阵引擎或Xe矩阵扩展则旨在加速人工智能工作负载。英特尔也形成了覆盖云计算、人工智能、5G、物联网、边缘计算和商用电脑的业务解决方案,并且其业务也覆盖了GPU的制造和封测环节,在台式机和笔记本电脑等领域也具备较客观的市场份额。但整体而言,英特尔的收入增速相对缓慢,受PC端出货量负面影响使得其在GPU这一核心业务增长动力不足。
高通等破局者投身GPU研发制造。以高通发布的第二代骁龙8旗舰移动平台(骁龙8 Gen 2)为例,其采用的新一代Adreno GPU相比上一代性能提升25%、功耗减少了45%,CPU的性能也提升了35%、功耗减少了40%,反映出了高通在GPU芯片设计领域已具备较快的迭代能力,包括华硕、荣耀、OPPO、小米、夏普、索尼、vivo等企业都将推出搭载骁龙8 Gen 2的产品。

头部大厂加速AI芯片布局,英伟达的潜在竞争对手或许是互联网头部厂商。我们发现,英伟达的竞争对手或许并不是目前正在研发GPU的专业厂商。互联网市场中的头部大厂,包括Google、阿里、微软、亚马逊和IBM等均在进行AI芯片研究。微软同时也在着手其AI芯片Athena的研发,为其OpenAI提供硬件支持。整体而言,如TPU、NPU的发展,同样适用于人工智能,因此英伟达的潜在竞争风险仍存,并不仅局限于GPU设计领域。
Google推出TPU,云端服务器提升深度学习计算效能。2014年起,Google开始自主研发AI专用芯片,并于2016年AlphaGo战胜李世石之后推出TPU (Tensor Processing Unit),TPU也成为近年来最火热的ASIC。TPU使用矩阵乘法阵列进行矩阵运算,在训练复杂神经网络过程中无须像GPU多次访问存储单元,并可以通过云TPU服务器进行跨设备操作。因此,TPU实现了将模型参数保存至同一高带宽存储器中,将调用的芯片的空间用以模型运算,降低了能耗并有效提升运行速度。直至2021年,Google已经推出了TPUv4,一定程度上阻滞了英伟达的市场需求增长。
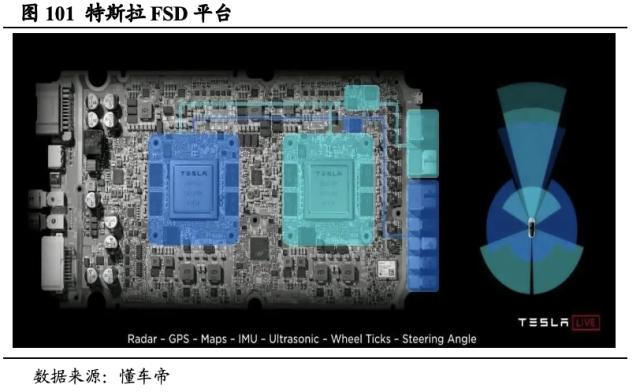
客户向竞争对手转变,特斯拉先后推出以NPU为基础的FSD车载芯片和D1芯片。NPU(Neural Network Processing Unit)在训练神经网络模型时相较GPU能耗和成本更低,并更适配嵌入环境,可减少神经网络运算过程的时间。2019年英伟达的重要客户特斯拉发布其自研FSD平台(Full Self-Driving Computer),搭载两块车载芯片,其中的最大组件NPU由特斯拉硬件团队定制设计,每个FSD芯片内均包含两个相同的NPU,一块GPU和一块CPU。2021年特斯拉发布D1芯片,并用其打造了AI超级计算机ExaPOD,对比英伟达对特斯拉的既有方案预算,拥有4倍的性能、1.3倍的能效比和仅1/5的体积。我们认为,FSD车载芯片和D1芯片的推出,标志着特斯拉对英伟达的芯片依赖度开始下降。
基于GPU相对低的成本和繁荣的生态,仍旧是超算的首位选择,短期内市场地位不会改变。以史为鉴,2017年Google推出Transformer模型,成为了OpenAI开发GPT-1的基础。此后英伟达迅速抓住全球算力需求爆发时机,推出搭载Transformer加速引擎的Hopper架构,同时推出H100 Tensor Core GPU,满足了超算的算力要求。整体而言,GPU的制造成本相比ASIC等AI芯片最低,生态也最繁荣。同时,由于目前模型正处在不断变化的飞速增长期,基于其较快的迭代速度,ASIC的定制化设计需要同时根据模型变化的新需求迭代,难以实现稳定的生产。因此GPU仍是解决AI算力的不二选择,短时间内其市场地位不会改变。
6.3. 以超异构创新构建面向大规模AI计算的系统性竞争优势
6.3.1. 超异构创新总览
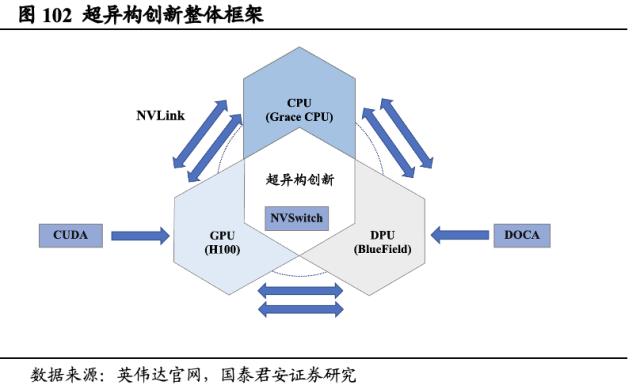
以超异构创新构建面向大规模AI计算的超级计算机。异构计算指是通过调用性能、结构各异的计算单元(包括CPU、GPU和各类专用AI芯片等)以满足不同的计算需求,实现计算最优化。我们认为,英伟达的核心竞争优势在于,构建了AI时代面向大规模并行计算而设的全栈异构的数据中心。英伟达NVLink性能快速迭代,同时NVSwitch可连接多个NVLink,在单节点内和节点间实现以NVLink能够达到的最高速度进行多对多GPU通信,满足了在每个GPU之间、GPU和CPU间实现无缝高速通信的需求,同时基于DOCA加速数据中心工作负载的潜力,实现DPU的效能提升,GPU +Bluefield DPU+Grace CPU的结合开创性地实现了芯片间的高速互联。同时CUDA充当通用平台,引入英伟达软件服务和全生态系统。我们认为,芯片和系统耦合的实现使得英伟达真正实现了超异构创新。
6.3.2. NVLink
首先,NVLink改变了传统PCIe复杂的传输过程,实现GPU与CPU的直接连接。以GH200超级芯片为例,其使用NVLink-C2C芯片互连,将基于Arm的Grace CPU与H100 Tensor Core GPU整合,从而不再需要传统的CPU至GPU PCIe连接。传统的PCIe需要经历由CPU到内存,再到主板,最后经过显存到达至GPU的过程。因此NVLink与传统的PCIe技术相比,将GPU和CPU之间的带宽提高了7倍,将互连功耗减少了5倍以上,并为DGX GH200 超级计算机提供了一个600GB的Hopper架构GPU构建模块。
6.3.3. DPU
DPU大幅降低CPU的负荷,为现代数据中心带来前所未有的性能提升。2020年,英伟达发布BlueField-2 DPU,将ConnectX-6 Dx的强大功能与可编程的Arm核心以及其他硬件卸载功能相结合,用于软件定义存储、网络、安全和管理工作负载。之后发布的BlueField-3 DPU更为强大,作为一款400Gb/s基础设施计算平台,其计算速度高达每秒400 Gb,计算能力和加密加速均较BlueField-2 DPU提高4倍,存储处理速度提高2倍,内存带宽也提高了4倍。同时,BlueField 系列DPU有助于降低能耗,在OVS平台上进行的一项测试中,在服务器最大荷载时,DPU能耗较CPU低29%。英伟达亦推出了融合加速器产品,结合其Ampere GPU架构和BlueField DPU的安全和网络增强功能。

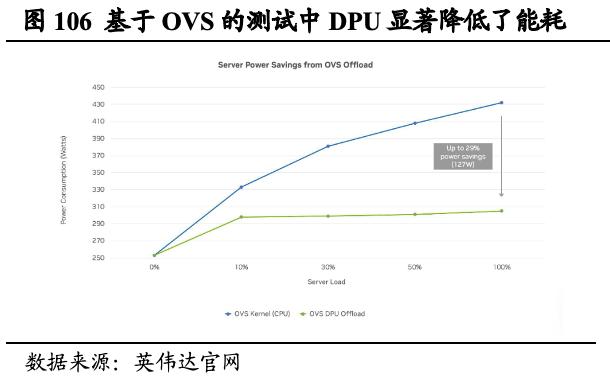
最新Spectrum-X 网络平台集英伟达Spectrum-4、BlueField-3 DPU 和加速软件于一身。Spectrum-X是基于网络创新的新成果而构建,将Spectrum-4以太网交换机与英伟达BlueField-3 DPU紧密结合,网络平台具有高度的通用性,可用于各种AI应用,它采用完全标准的以太网,并与现有以太网的堆栈实现互通,全球头部云服务提供商都可采用该平台来横向扩展其生成式AI服务。我们认为,Spectrum-X的上市将进一步提升英伟达以太网AI云的性能与效率,成为英伟达为AI工作负载扫清障碍的关键一环。
6.3.4. CPU
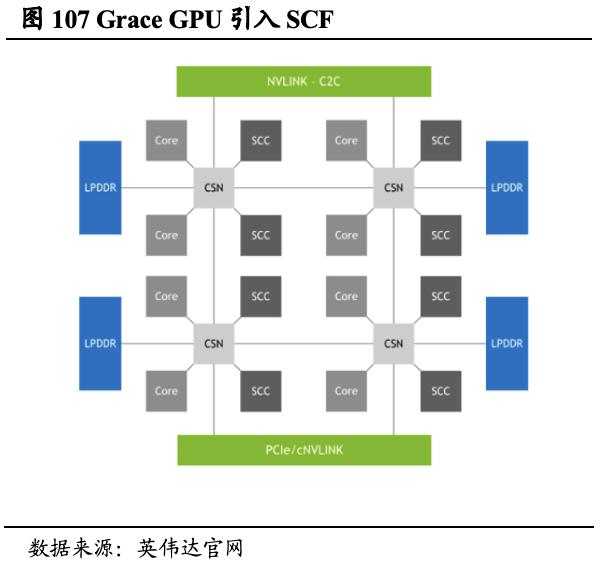
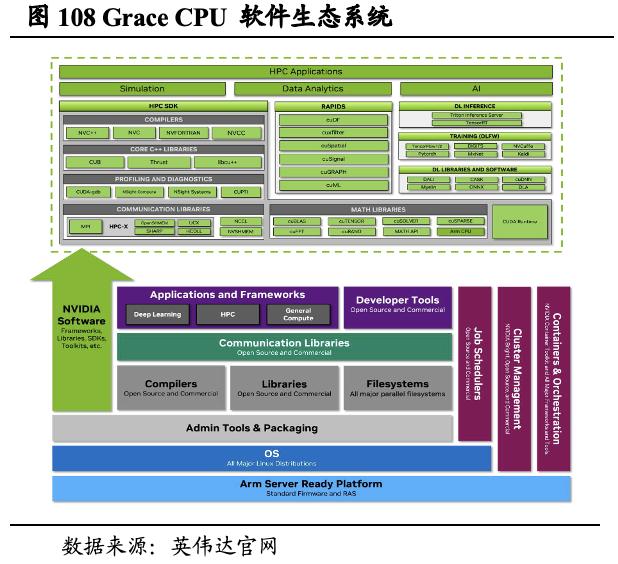
英伟达自研Grace CPU超级芯片,为AI数据中心而生。不同于传统的CPU,英伟达Grace CPU采用NVLink C2C技术,是一款专为数据中心而设计的CPU,其可运行包括AI、高性能计算、数据分析、数字孪生和云应用在内的工作负载。Grace CPU 可提供144个Arm Neoverse V2核心和1 TB/s的内存带宽,并引入了可扩展一致性结构 (SCF),SCF 可用以确保 NVLink-C2C、CPU内核、内存和系统IO之间的数据流量流动。从软件角度,英伟达Grace CPU软件生态系统将用于CPU、GPU 和DPU的全套英伟达软件,与完整的Arm数据中心生态系统相结合。
6.3.5. “GPU+DPU+CPU”的三芯战略
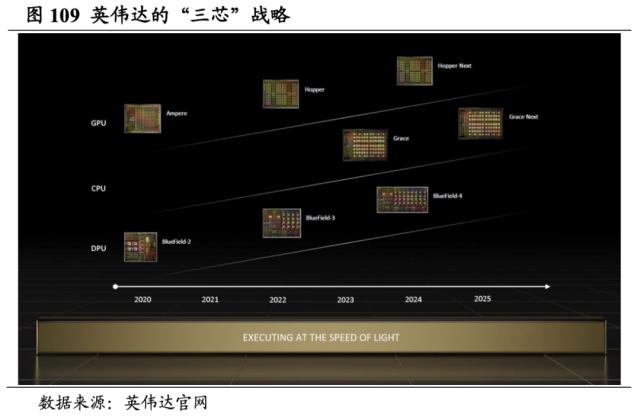
综上,英伟达基于“GPU+DPU+CPU”的三芯战略已初步实现,软件和硬件相互支持,成为AI发展的技术标杆。我们认为,英伟达的商业模式正在由销售“硬件+软件”的制造商向大规模AI计算的平台公司持续转型,持续通过基于异构计算的硬件迭代加软件服务的整体生态更新提升运算速度,降低运算成本。英伟达通过“GPU+DPU+CPU”构建英伟达加速计算平台,和传统服务器的计算系统相比,加速计算系统新增添了GPU和DPU,为包括AI和可视化等现代业务应用提供计算加速器支持。英伟达亚太区开发技术部总经理李曦指出,目前世界上只有5%的计算任务被加速,而未来十年所有的计算任务都将被加速,还会诞生十倍于现阶段的新计算任务,这将为加速计算市场带来超100倍的增长空间。


6.3.6. CUDA和DOCA
CUDA和DOCA打造软件生态,进而与硬件组成全栈系统优势。如前所述,CUDA可以充当英伟达各GPU系列的通用平台,因此开发者可以跨GPU配置部署并扩展应用。借助于CUDA的高兼容性,英伟达成功将GPU的应用领域拓展至计算科学和深度学习领域。而DOCA的最主要功能为加速、卸载并将数据中心基础架构DPU隔离,真正充分发挥了人工智能的潜力,推动数据中心转向加速计算,以满足日益增长的计算需求。
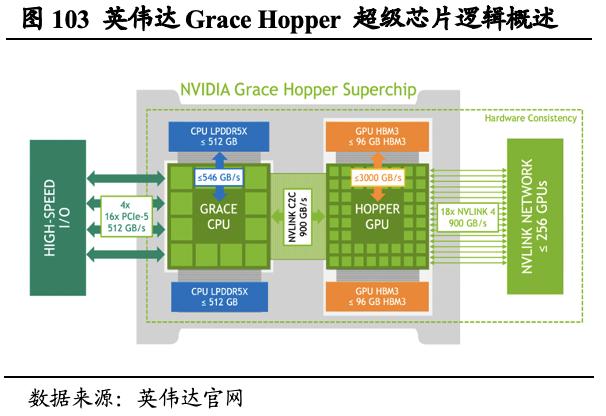
6.3.7. GH200
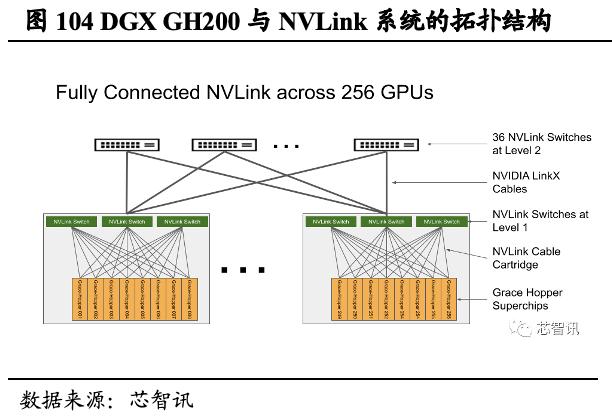
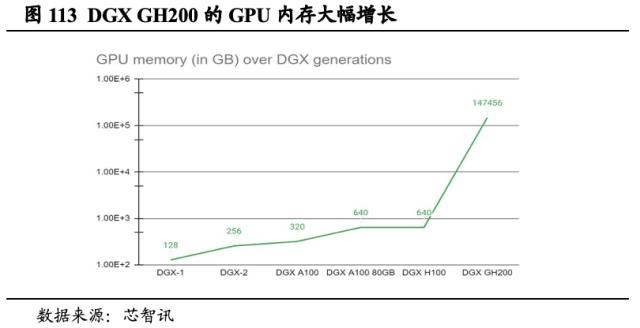
基于超异构创新,英伟达发布能提供超强AI性能的DGX GH200大内存AI 超级计算机。DGX系统利用全堆栈解决方案和企业级支持,为企业AI基础架构设定标杆,是应用于TOP500中多台超级计算机的核心基础模组。DGX GH200作为最新产品,整合了Grace CPU和H100 GPU,拥有近2000亿个晶体管,通过定制的NVLink Switch System将256个GH200超级芯片和高达144TB的共享内存连接成一个单元,使DGX GH200系统中的256个H100 GPU作为一个整体协同运行。DGX GH200提供1 exaflop性能与144 TB共享内存,比单个DGX A100 320GB系统高出近500倍。这让开发者可以构建用于生成式AI聊天机器人的大型语言模型、用于推荐系统的复杂算法,以及用于欺诈检测和数据分析的图形神经网络。

GH200超级芯片是英伟达系统性竞争优势的集大成者。我们认为,GH200超级芯片集合了最先进的Grace Hopper架构,并应用第四代Tensor Core提升计算性能、进行模型优化,NVLink实现了高速的传输,这都将进一步形成英伟达的竞争壁垒。随着Grace Hopper超级芯片的全面投产,全球的制造商很快将会提供企业使用专有数据构建和部署生成式AI应用所需的加速基础设施。谷歌云、Meta 和微软是首批有望接入DGX GH200的企业。
总的来说,英伟达作为龙头企业将大比例享受AI芯片行业整体需求高增带来的红利。如本报告先前所述,IDTechEx预测2033年全球AI芯片市场将增长至2576亿美元。JPR预测2022-2026年全球GPU销量复合增速将保持在6.3%水平。摩根大通的预测认为,英伟达将在2023年的人工智能产品市场中获得60%的份额,主要来自于GPU和网络互连产品。因此,英伟达作为人工智能产业的上游龙头供应商,我们看好市场需求的激增对于英伟达产品的爆发式需求增长。以超异构创新研发能力优势和业内领先的生态,以及对于以生成式AI为代表的人工智能迅速带来业务变革的准确把握,其依旧具备市场领先的地位,短时间内其龙头地位不会改变。
7
数据中心助推营收超预期,
市值突破开创新高点
7.1. 营收指标增势明显,盈利能力优势充分彰显
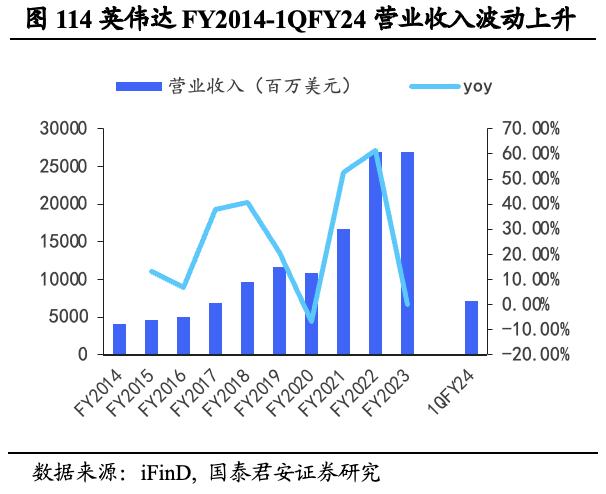
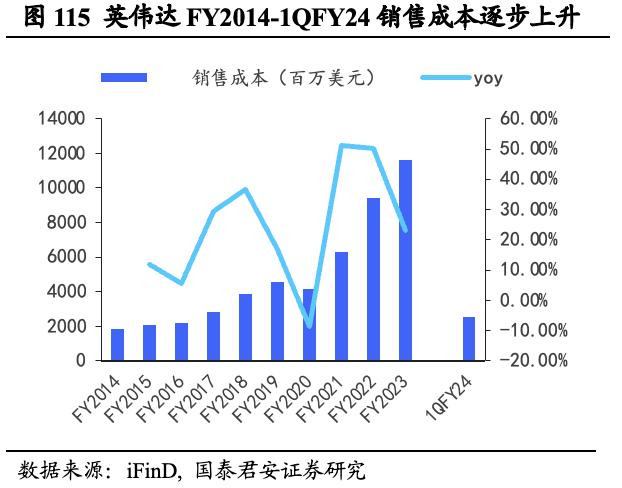
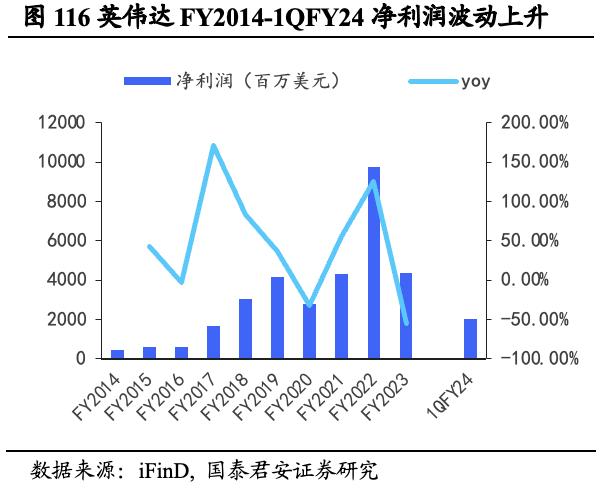
营收及利润波动较大,盈利能力增长可期。英伟达FY2022/FY2023/1QFY24营业收入分别为269.14/269.74/71.92亿美元,同比+61.40%/ +0.22%/ -13.22%;FY2022/FY2023/1QFY24销售成本为94.39/116.18/25.44亿美元,同比+50.33%/ +23.09%/ -10.96%; FY2022/FY2023/1QFY24净利润为97.52/ 43.68/ 20.43亿美元,同比+125.12%/-55.21%/+26.27%。营业收入和净利润近年来整体呈波动上升趋势,呈现较大波动特征,尤其FY2023净利润出现大幅下跌,不及FY2022一半。但1QFY24营收增长超预期明显,未来盈利能力有望持续高增。
销售毛利率和净利率增势明显,但2023财年出现小幅下跌。公司FY2022/FY2023/1QFY24销售净利率分别为36.23%/16.19%/28.41%,同比+10.25pct/ -20.04pct/ +8.89pct,销售毛利率分别64.93%/56.93%/64.63%,同比+2.59pct/-8.00pct/+0.90pct,整体保持积极增速,但FY2023呈现一定跌幅。1QFY24,销售毛利率和净利率再度回升。

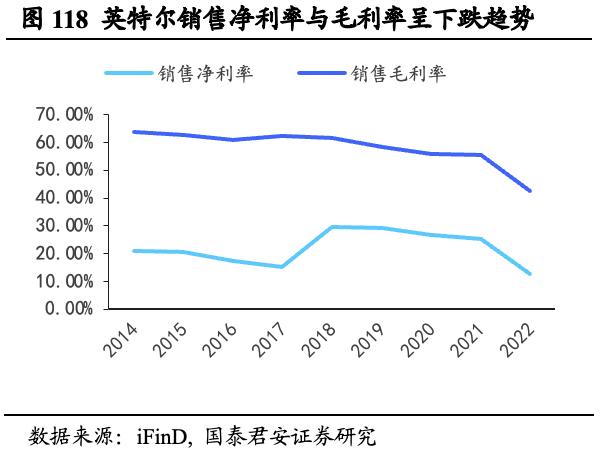
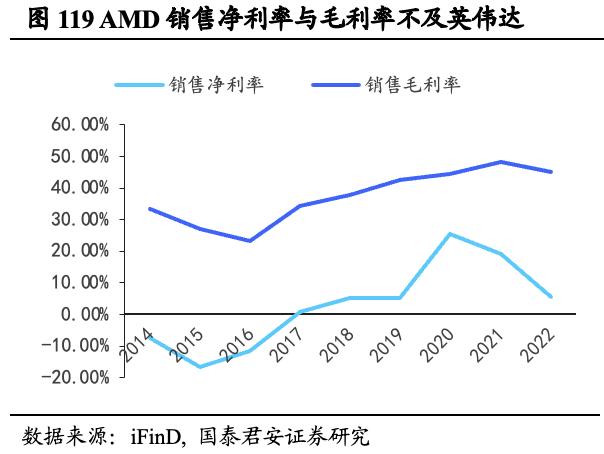
英伟达销售毛利率和净利率显著高于英特尔和AMD,彰显盈利能力优势。对比公司两大竞争对手英特尔和AMD:英特尔2022年销售净利率12.71%,销售毛利率42.61%;AMD销售净利率5.59%,销售毛利率44.93%,二者均低于英伟达在FY2023的表现,反映英伟达相比主要竞争对手具备更高的盈利能力。
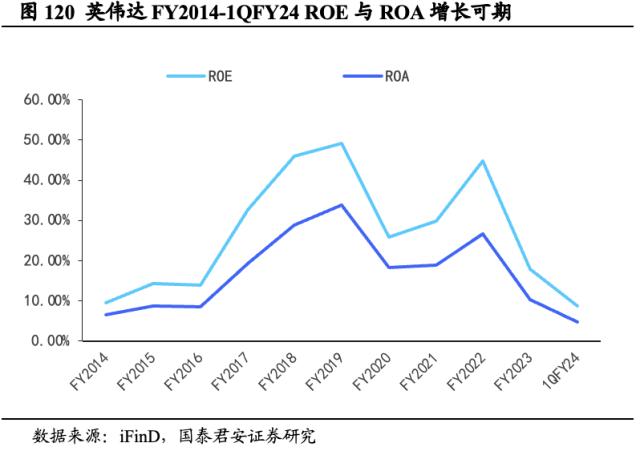
英伟达FY2023营收与利润下跌因素逐步化解,看好公司长期盈利能力。FY2022/FY2023/1QFY24英伟达ROE分别为44.83%/17.93%/8.76%,ROA分别为26.73%/ 10.23%/ 4.77%,公司FY2023盈利能力层面逆风。我们认为,英伟达FY2023营收不及预期主要由游戏收入下降导致,2020年受全球疫情影响,显卡市场炒作情绪狂热,显卡价格一路飙升,而随着疫情影响逐步减弱,显卡市场需求导向转向疲弱。同时黄仁勋指出,中国市场业务受阻也极大影响了英伟达营收表现,但随着宏观逆风因素逐步消散,以及2022年末GPT席卷行业带来的需求激增,我们认为英伟达在2024财年营收有望得到持续改善。
7.2. GPT带动市值高增,股价转向上升通道
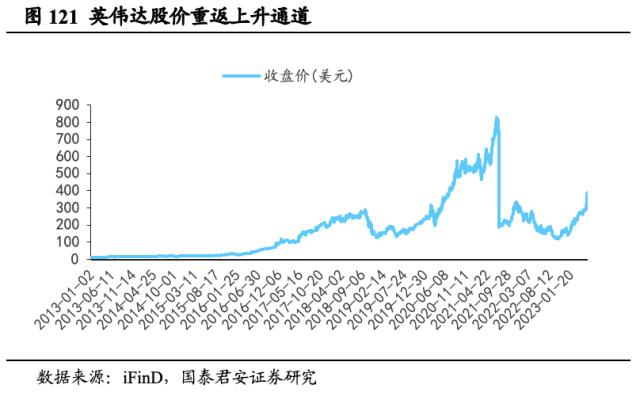
股价重返上升通道,盈利能力持续释放。英伟达股价2013年1月2日仅12.72美元,2016年起一路高增,2018年末回调后自2019年年终起再度踏入上升通道(注:图中收盘价在2021年7月20日直线下跌是由于英伟达当日以1:4的比例拆分股票所致)。2022年初,受业绩预期放缓影响,英伟达股价呈较明显下跌趋势,自2023年年初起,市场逐步对英伟达投资价值形成一致预期,伴随着价值挖掘深入,潜在盈利能力有望持续释放。2023年5月25日,受一季报营收超预期和2QFY24应用收入展望达110亿美元影响,英伟达股价迅速高增至379.8美元。
公司市值受GPT带动一路高升。伴随着公司股价高涨,英伟达股票市值爆发式抬升。截至2023年5月26日,英伟达市值约9630亿美元,而同日英特尔市值约1230亿美元、AMD市值约1700亿美元,英伟达市值处行业龙头水平,已远超英特尔与AMD市值之和。
7.3. 数据中心成为盈利主要驱动,成就营收高增奇迹
数据中心业务营收占比过半,成为营收增长的主要驱动因素。据英伟达财报,英伟达将其主营业务分为四大领域,分别是数据中心、游戏、专业视觉、汽车和嵌入式技术。FY2023上述四大业务营收分别为150.1/90.7/15.4/9.03亿美元,同比+41%/-27%/-27%/+60%。1QFY2024四大业务营收分别为42.8/22.4/2.95/2.96亿美元,同比+14%/ -38%/ -53%/ +114%,数据中心和游戏业务为英伟达营业收入的最主要来源。其中,FY2023Q2起游戏业务大幅下跌,此后的三季度依旧低位徘徊,对全年营收造成较大负面影响。但整体而言,数据中心业务高增速推动了营收的高增量,部分缓解了游戏业务低迷对营收增长的阻滞。

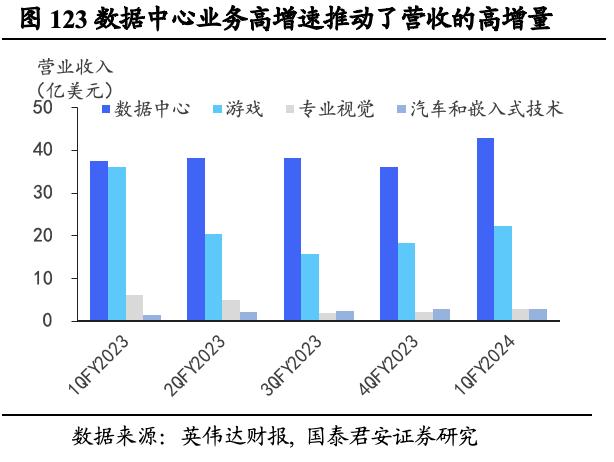
大模型训练催生算力需求,英伟达当下在模型训练和推理中的地位短期不会改变。对于以ChatGPT为代表的AI产业,英伟达已形成CPU+GPU+DPU的硬件组合,并已CUDA软件平台为基石打造应用生态。1QFY24中英伟达推出的四款推理平台,这些平台将英伟达的全栈推理软件与最新的 NVIDIA Ada、NVIDIA Hopper和NVIDIA Grace Hopper处理器结合在一起,更加稳固了英伟达在模型训练和推理中的地位。英伟达表示,云服务商对公司的基础架构十分感兴趣,英伟达直接与全球近一万家人工智能初创公司合作,同时随着经济好转,宏观逆风逐渐消散,企业上云的进程将会恢复。我们认为,其数据中心业务未来盈利可期。
8
投资建议
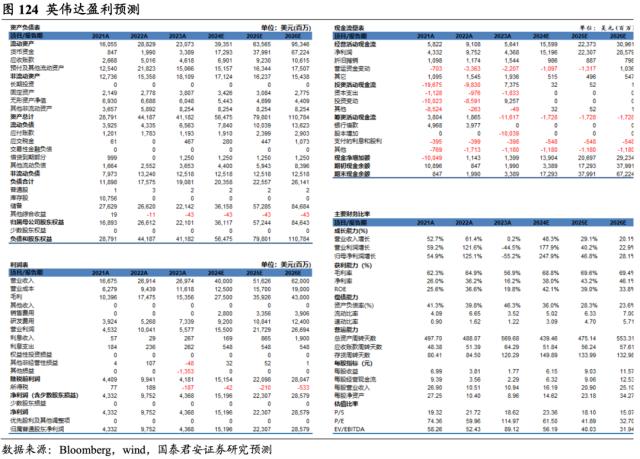
行业龙头当仁不让,英伟达盈利能力可期。考虑到英伟达1QFY2024营收的出色表现,包括数据中心收入创下42.8亿美元的纪录,以及英伟达自身对于2QFY2024的收入展望达110.0亿美元的乐观预期,我们预计公司FY2024E/FY2025E/FY2026E营业收入分别为400.0/516.26/620亿美元,同增48.29%/29.07%/20.09%,FY2024E/FY2025E/FY2026E经调整净利润分别为151.96/223.07/285.79亿美元,同增247.89%/ 46.80%/ 28.12%。
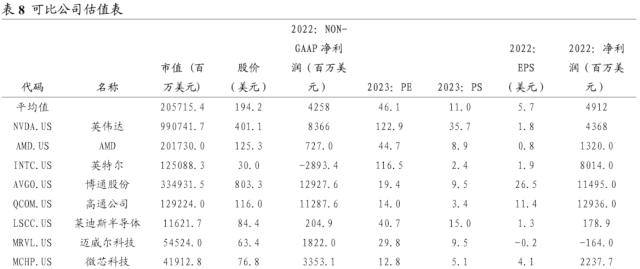
估值方面,我们选取全球半导体市场的头部企业作为英伟达的可比公司。结合彭博的一致预测,可比公司 2023E 平均 PE 46.1X。英伟达作为业内有目共睹的头部公司,在图形处理领域拥有超群的技术实力和领导地位,产品生态具备显著的稀缺性。同时,在此次人工智能的大浪潮中,英伟达将在算力领域充分受益,客户需求递增,强大的生态系统使得其他竞争对手难以复制。因此我们给予其超出行业平均的 PE 70.0X,首次覆盖,并给予“增持”评级。

5
风险提示
AI 应用发展不及预期;公司研发进度不及预期;地缘政治冲突影响产品销售。
关键词阅读:英伟达




- 银行股迎来“黄金买点”?摩根大通预计下半年潜在涨幅高达15%,股息率4.3%成“香饽饽”
- 华润电力光伏组件开标均价提升,产业链涨价传导顺利景气度望修复
- 我国卫星互联网组网速度加快,发射间隔从早期1-2个月显著缩短至近期的3-5天
- 光伏胶膜部分企业上调报价,成本增加叠加供需改善涨价空间望打开
- 广东研究通过政府投资基金支持商业航天发展,助力商业航天快速发展
- 折叠屏手机正逐步从高端市场向主流消费群体渗透
- 创历史季度新高!二季度全球DRAM市场规模环比增长20%
- 重磅!上海加速推进AI+机器人应用,全国人形机器人运动会盛大开幕,机器人板块持续爆发!
- 重磅利好!个人养老金新增三大领取条件,开启多元化养老新时代,银行理财产品收益喜人!
- 重磅突破!我国卫星互联网组网速度创新高,广东打造太空旅游等多领域应用场景,商业航天迎来黄金发展期!


